Automatic Recognition and Understanding of the Driving Environment for Driver Feedback
People
Description

In this project we investigate advanced concepts to develop techniques for building internal models of both the vehicle's static environment (objects, features, terrain) and of the vehicle's dynamic environment (people and vehicle moving in the vehicle's environment) from sensor data, which can operate online and can be used to assist the driver by providing the information necessary to make recommendations, to generate alarms, or to take emergency actions. Our overall approach is to combine recent progress in machine perception with the rapid advent of onboard sensors, and the availability of external data sources, such as maps.
2. Approach
The first component of our approach is to extend state-of-the-art machine perception techniques in three areas:
- Scene understanding from images in which objects, regions, and features are identified based on image input.
- Scene understanding from the type of 3D point clouds acquired from, for example, stereo or Lidar systems.
- Analysis of moving objects which includes the ability to predict likely future motions in addition to modeling the current trajectory.
The second component of our approach is to maximize the use of external sources of information.
We have started by using current map data from navigation systems to generate priors on
distribution of features and objects in the environments, and to generate priors of
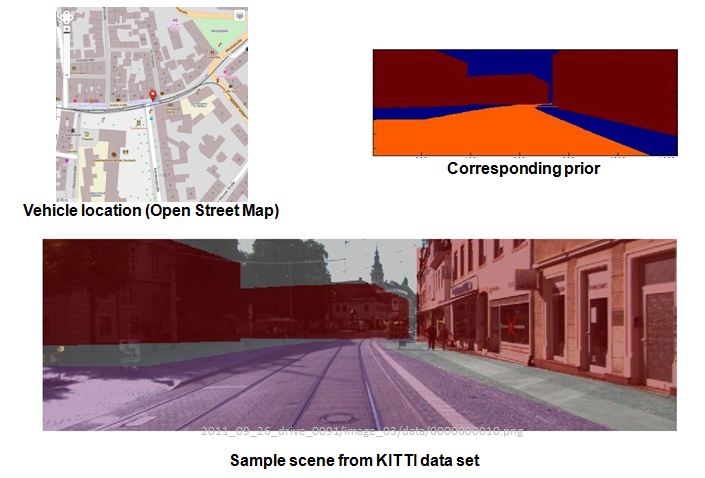
pedestrian and tracking activity. An example is shown in the following figure, where
priors of roads and buildings, obtained from an external map, are overlaid on top
of the image.
Static scene understanding
One of the goals of our research is to investigate how to boost the performance of machine
perception techniques through the use of priors obtained from external sources of information.
Our initial objective is to test our algorithms using priors generated from maps by comparing the
labeling performance with and without this information. Since maps do not contain information
about dynamic elements of the scene (e.g. cars and pedestrians), we focus on the static elements, whose
information is available in the maps.
To this end, we have initially concentrated on the use of video cameras as the primary sensor. We have
leveraged work done recently in semantic labeling from images. In particular, we use the
Stacked Hierarchical Labeling algorithm [1], which is based on the
decomposition of an image to encode spatial and relational information.
A sample output from the semantic labeling from images is shown in the following figure. As shown,
regions in the image are colorized according to which class they belong to.

Generation of priors
As mentioned above, we use maps to generate priors on locations where buildingas and roads are likely to occur. Given the vehicle's location, the information from the context in the vicinity is imported from Open Street Map, and then a synthetic image is generated. From this virtual image, a set of priors for roads and buildings is obtained. This process is illustrated in the following image:

To generate the synthetic image, it is important to acocunt for the vehicle's postion uncertainty. Otherwise, the synthetic image will not match the observation from the vehicle, and the resulting priors will be incrorrect. We process the vehicle's position measurement from GPS using a Kalman Filter, and use the estimates of position and heading uncertainty to calculate the prior. This has the effect of "diluting" the priors when the uncertainty is high, as shown in the following figure:

3. Results
We investigated approaches to generate priors based on a maximum entropy framework. This approach is
suitable for our purposes because different sources of information can contribute with different
elements for any given scenario, yet, it is not guaranteed that all the elements in the scene will
be represented in every source.
Similarly, we have explored several approaches to incorporate the prior distribution into the scene parsing algorithm.
These include a combination of probabilities using Product of Experts, re-weighting the label probability
distribution using prior contexts using a ensamble of classifiers, and appending the prior probability onto
the feature stacks of the Hierarchical Inference Machine[1]. Preliminary results obtained using a small set of urban street scenes
from the KITTI Vision Benchmark dataset are shown in the following figure, where two approaches of incorporating priors are compared:
re-weighting using logistic regression, and appending prior into hierarchical inference machine:

Reference
- [1] Stacked Hierarchical Labeling, European Conference on Computer Vision
D. Munoz, J.A. Bagnell, and M. Hebert.
ECCV, September, 2010.
[Paper (PDF)], [BibTeX]
 |
| Paper |
Funding
- U.S. DoT University Transportation Center Grant DTRT12GUTC11