
This project aims to perform neural style transfer by building on the VGG-19 convolutional neural network. We try to optimize the loss in content space and style space, then combine the two to enable transferring of style from a style image to a content image.
The implementation of the style transfer algorithm is as follows:
For content loss, I used nn.MSELoss to calculate mean squared error for the image and target, after a layer. For style loss, I implemented the Gram matrix by:
Then, I used the MSE loss of the Gram matrix of the input and target as the style loss.
To selectively disable content or style loss, I enclosed the calculation of both losses in conditionals inside the run function. When one of the losses is disabled, its value will be 0 instead.
I relied on the tutorial for neural style transfer at https://pytorch.org/tutorials/advanced/neural_style_tutorial.html for my implementation of the network itself.
For content loss, the best results for image reconstruction were seen using conv1 - essentially just pixel loss. A comparison is shown below:
conv1
conv3

conv5

conv7

This does not work well, however, for style transfer, as the criterion is too strict, leading to the optimizer unable to converge and generating images with subpar content quality. For the actual style transfer, I used conv layers 11, 13 and 15, which seems like pure noise when not used with style loss.
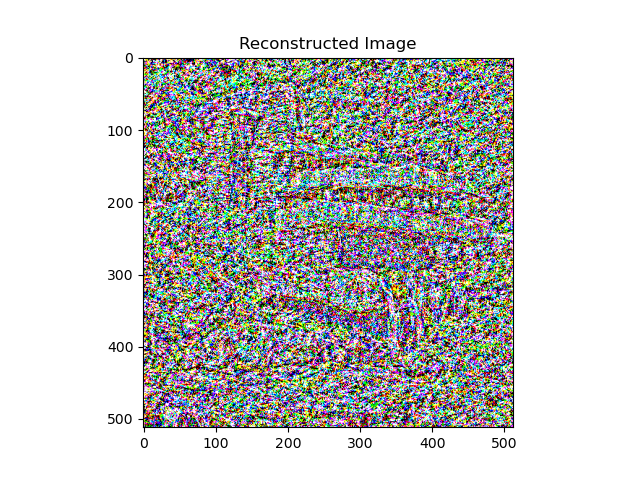
Another image I managed to reconstruct using content loss:

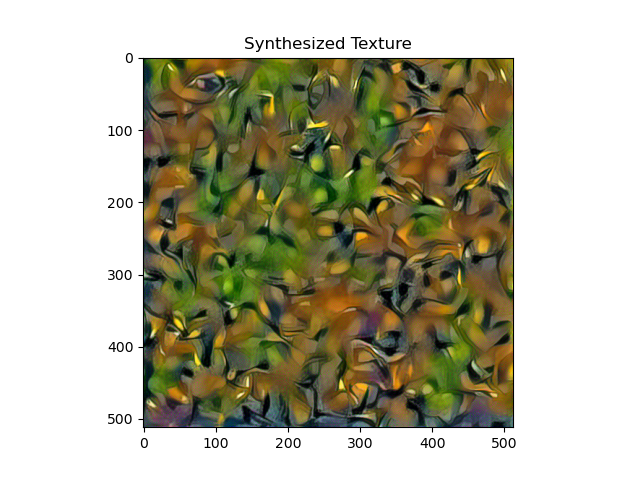
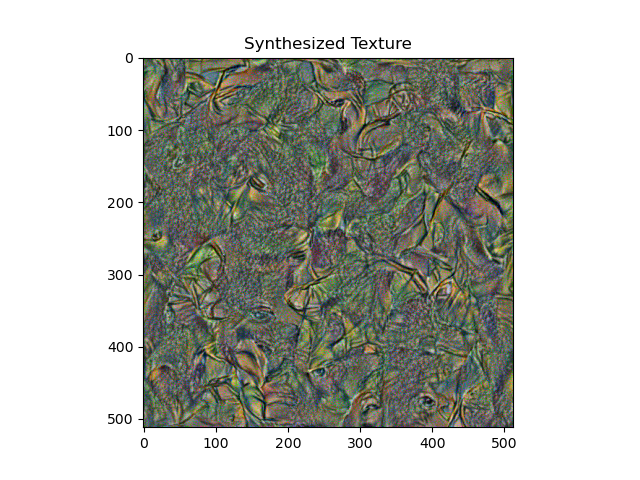
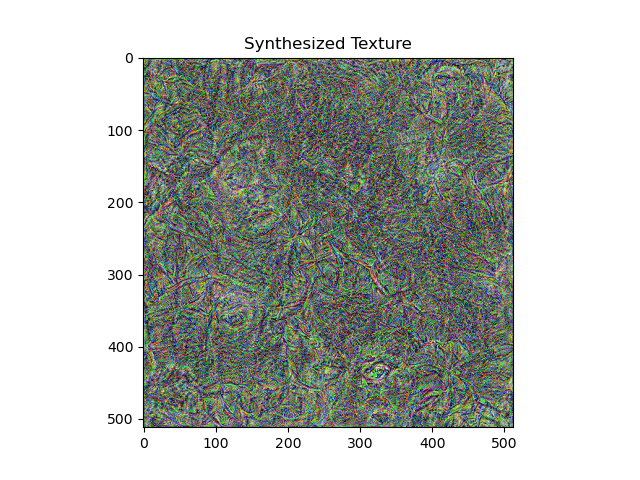
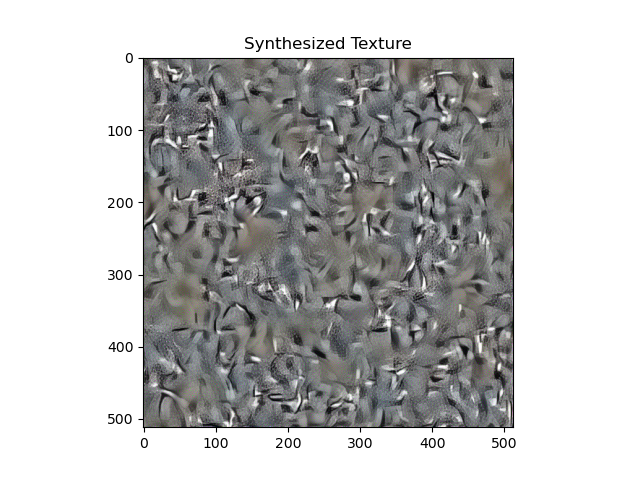
For style loss, I tried placing 5 style layers at 1-5, 6-10, and 11-15 respectively. 1-5 gave the best textures, and are also the ones that work best in the style transfer pipeline. A comparison is shown below:
1-5
6-10
11-15
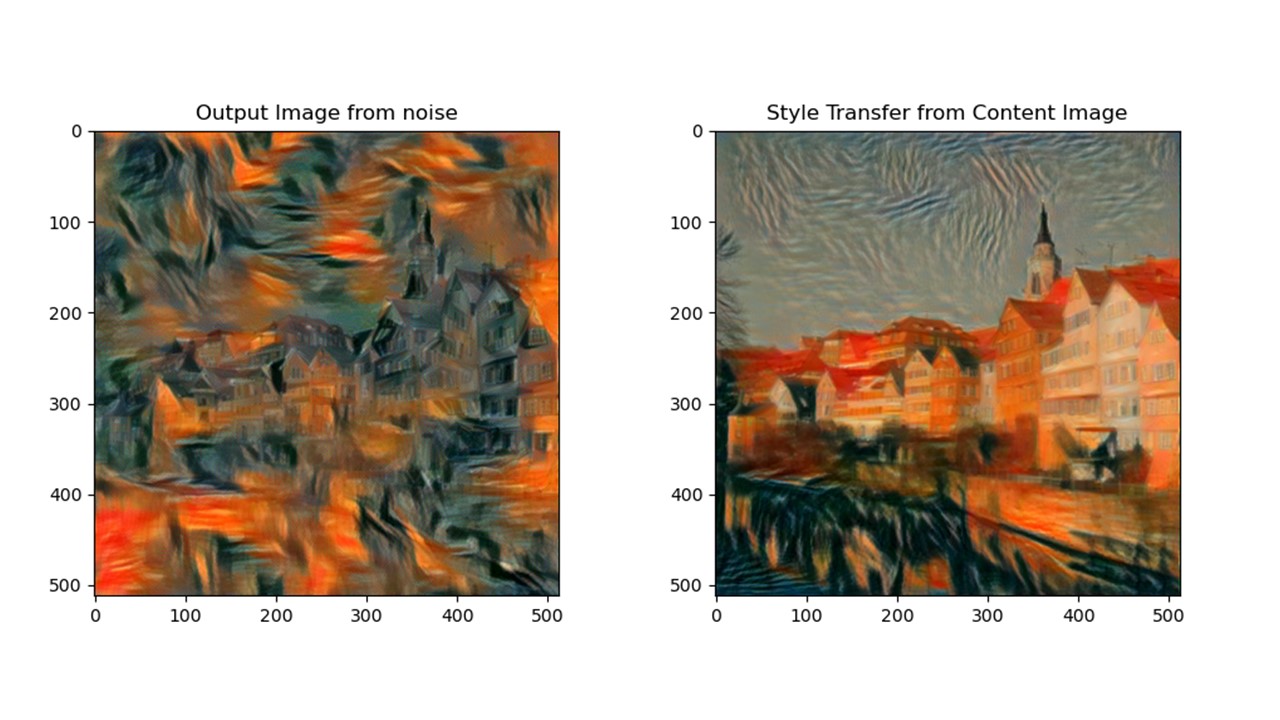
The best hyperparameters that I was able to find in this step was using conv 9, 11, 13 and 15 for content loss and conv 1-5 for style loss. This enabled me to preserve content very well while adding on realistic style.
Results are shown below:

For inputting random noise versus content image, I found that generating images from noise generally returns more abstract results, while generating images from content image returns something more faithful to the original image in detail. Both of them have merits in different art styles.
One of the instances where I preferred noise better was transferring the style of The Scream by Edvard Munch onto a landscape. The two results, shown below, show that the noise-generated image looks more similar to what Munch would have drawn himself, with dramatically distorted geometry.
The opposite goes for other cases, like this style transfer of Frida Kahlo's Self Portrait onto a dancer. In this one, since the artist's style is a lot more similar to real life imagery than the previous case, the image-generated result works much better.

I was also able to add my own cat pictures and desired styles to the pipeline.


One last thing I wanted to try to do was to turn a picture of a sleeping cat that I took, inspired by chiascuro lighting in Renaissance paintings, into an actual Renaissance piece. To do this, I carefully selected a single subject of Caravaggio's The Calling of St. Matthew that matched the lighting conditions of my photo for the style image, and I edited the original image in Lightroom to lower the exposure and increase the contrast to maximum, to match the dramatic lighting in the painting. Performing style transfer on these two images yields this result:

I find this result quite realistic and beautiful, as the painting's brushwork and color can be seen clearly on the final product, with the chiascuro effect particularly visible and realistic thanks to the manual matching I did beforehand, giving it a dramatic 3D effect exceeding even that of the original photo.
I name this computer-generated painting The Calling of St. Catthew.