Assignment #4 - Neural Style Transfer¶
If you complete any Bells and Whistles, please point out at the top of your website.
- Stylize your grump cats or Poisson blended images from the previous homework. (2pts)
- Use a feedforward network to output style transfer results directly (8 pts). You can use or modify the CycleGAN generator network used in HW3. Perceptual Losses for Real-Time Style Transfer and Super-Resolution, Johnson et al. 2016
Introduction¶
Nerual style transfer is a technique that generates an image with the content of one image and the style of another image. The algorithm takes in a content image, a style image, and another input image. The input image is optimized to match the previous two target images in content and style distance space.
This assignment contains three parts: in the first part, I implemented the optimization process to generate an image that matches the content of a content image. In the second part, I implemented the optimization process to generate an image that matches the style of a style image. In the last part, I combined the two optimization processes to perform neural style transfer.1
Part 1: Content Reconstruction [30 points]¶
For the first part of the assignment, I implemented content-space loss and optimize a random noise with respect to the content loss only.
Experiment:
- Report the effect of optimizing content loss at different layers. [15 points]
Answer: If the layer that is used to calculate the content loss is more close to the input layer, the generated image will be less noisy and more similar to the content image. The name of the layer conv_i indicates the first convolutional layer in the $i$-th block of the VGG19 network.
For example, the following results are generated by optimizing the content loss at different layers from the same content image (phipps.jpeg) and the same random noise image.
| Layer | Image |
|---|---|
| conv_1 |  |
| conv_2 |  |
| conv_3 |  |
| conv_4 | 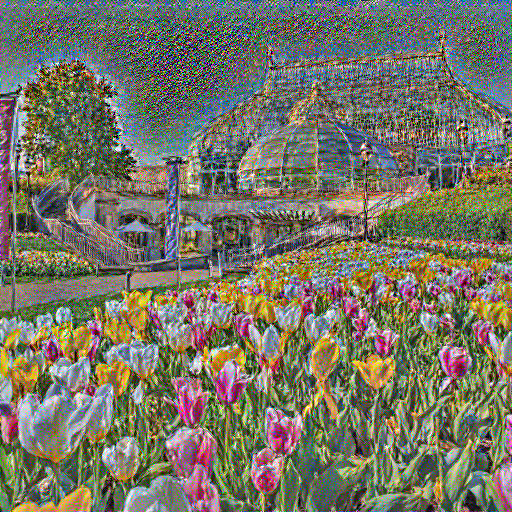 |
- Choose your favorite one (specify it on the website). Take two random noises as two input images, optimize them only with content loss. Please include your results on the website and compare each other with the content image. [15 points]
Answer: The following results are generated by optimizing the content loss at the conv_4 layer from the same content image (tubingen.jpeg) and two di1fferent random noise images.
| Content Image | Random Noise 1 | Random Noise 2 |
|---|---|---|
 |
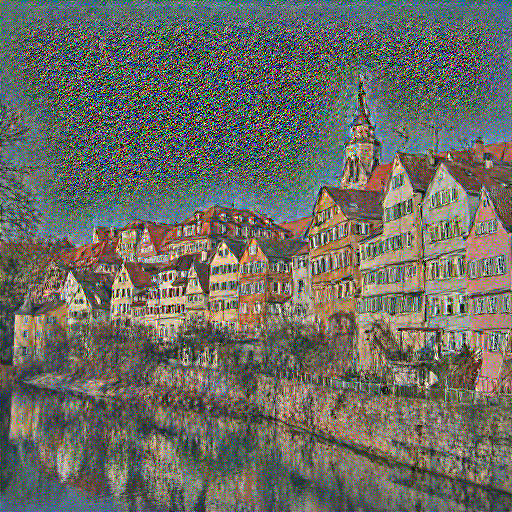 |
 |
Two reconstructed images are similar to the content image but have different noise patterns.
Part 2: Texture Synthesis [30 points]¶
Experiment:
- Report the effect of optimizing texture loss at different layers. Use one of the configurations; specify it in the website and: [15 points]
Answer: If the layer that is used to calculate the style loss is more close to the input layer, the generated texture will be more sharp and fine-grained. If the layer is more close to the output layer, the generated texture will be more coarse and abstract. The following results are generated by optimizing the style loss at different layers from the same style image (starry_night.jpeg) and the same random noise image.
| Layer | Image |
|---|---|
| conv_1 |  |
| conv_2 |  |
| conv_3 |  |
| conv_4 |  |
| conv_5 |  |
As we can see, the texture generated by optimizing the style loss at the conv_4 layer is more sharp and fine-grained. And the image generated by optimizing the layer closer to the input layer tend to capture more low-level and coarse features, such as colors.
- Take two random noises as two input images, optimize them only with style loss. Please include your results on the website and compare these two synthesized textures. [15 points]
Answer: The following results are generated by optimizing the style loss at the conv_2 layer from the same style image (the_scream.jpeg) and two different random noise images.
| Style Image | Random Noise 1 | Random Noise 2 |
|---|---|---|
 |
 |
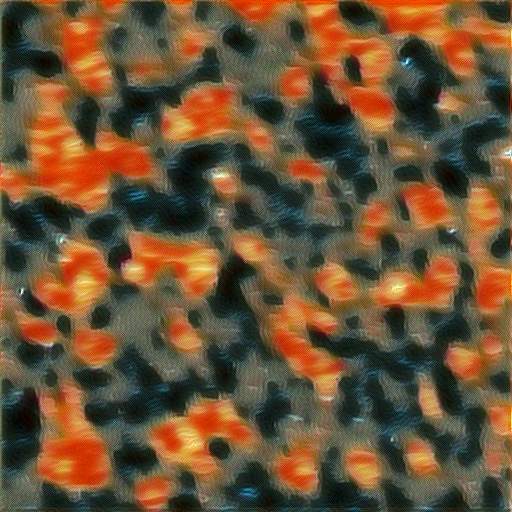 |
As we can see, the two synthesized textures are similar to the style image but have different texture patterns.
Part 3: Style Transfer [40 points]¶
Experiment:
- Tune the hyper-parameters until you are satisfied. Pay special attention to whether your gram matrix is normalized over feature pixels or not. It will result in different hyper-parameters by an order of 4-5. Please briefly describe your implementation details on the website. [10 points]
Answer: I apply the content loss on the feature maps of the conv_4 layer and the style loss on the feature maps of the conv_1, conv_2, conv_3, conv_4, conv_5 layers. The content image is the tubingen.jpeg image and the style image is the starry_night.jpeg image. The optimization number of iterations is 300, the content_weight is 1.0.
The hyper-parameters and the results are as follows:
| style_weight=1 | style_weight=1000 | style_weight=10000 | style_weight=100000 |
|---|---|---|---|
 |
 |
 |
 |
| style_weight=500000 | style_weight=1000000 | style_weight=10000000 | style_weight=1000000000 |
 |
 |
 |
 |
As we can see, due to the normalization on the gram matrix and I divide the style loss by the number of the feature maps, although change the style weight by an order of 4-5, the results are similar and acceptable.
- Please report at least a 2x2 grid of results that are optimized from two content images mixing with two style images accordingly. (Remember to also include content and style images therefore the grid is actually 3x3) [10 points]
Answer: The following results are generated by optimizing the content loss on the feature maps of the conv_4 layer and the style loss on the feature maps of the conv_1, conv_2, conv_3, conv_4, conv_5 layers from two content images (phipps.jpeg and wally.jpeg) and two style images (escher_sphere.jpeg and picasso.jpeg). The content weight is 1 and the style weight is 1000000.
| original style |  |
 |
|---|---|---|
| original content | ||
 |
 |
 |
 |
 |
 |
- Take input as random noise and a content image respectively. Compare their results in terms of quality and running time. [10 points]
Answer: The following results are generated by optimizing the content loss on the feature maps of the conv_1 layer and the style loss on the feature maps of the conv_2 layers from the same content image (wally.jpeg) and style image (picasso.jpeg). One input is the random noise and the other input is the content image. The content weight is 1 and the style weight is 1.
| input from noise | input from content |
|---|---|
 |
|
- Time taken for style transfer from noise: 168.982262134552 s
- Time taken for style transfer from content: 168.95274114608765 s
As we can see, the results are similar in terms of running time, but the result from the content image is more stable since it remains the content structure.
- Try style transfer on some of your favorite images. [10 points]
Answer: The following results are generated by optimizing the content loss on the feature maps of the conv_4 layer and the style loss on the feature maps of the conv_1, conv_2, conv_3, conv_4, conv_5 layers from some of my images.
| content image | style image | result |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
Bells & Whistles (Extra Points)¶
- Stylize your grump cats or Poisson blended images from the previous homework. (2pts)
| grump cat | style: the scream | result |
|---|---|---|
 |
|
 |
- Use a feedforward network to output style transfer results directly (8 pts). You can use or modify the CycleGAN generator network used in HW3. Perceptual Losses for Real-Time Style Transfer and Super-Resolution, Johnson et al. 2016
Answer: I use the CycleGAN generator network to output style transfer results directly. The following results are generated by the CycleGAN feedforward network training on specific style images and content images.
In the original paper, they used transformer networks to perform feed forward style transfer, and trained the network on a large dataset MS COCO. However, with limited computational resources, I only trained the network on the homework 3 grump cats dataset B and tested transfer on the grump cats dataset A. Since the dataset is very small and the resolution is quite low, the results are not as good as the paper or the optimization method. The style weights is 1e5 and the content weights is 1. Using Adam optimizer with learning rate 1e-4 and the number of epochs is 6.
| training style | result |
|---|---|
 |
 |
|
 |
 |
 |
The training process takes about 1 minute and the test process takes about 1 second. The results are acceptable and the feedforward network is efficient.