Improving Image Representations of Words through Region-specific Loss Minimization
CMU 16-726: Learning-based Image Synthesis
Ming Chong Lim (mingchol), Shao Xuan Seah (sseah)
Introduction
Generative models have shown remarkable capability in creating high-fidelity representations of semantic objects.
However, when it comes to generating textual content, especially alphabets within images, these models often falter, and the challenge lies in the inherent difficulty of understanding the significance of accuracy in graphical word representations.
Typically, semantic representations are mapped to token embeddings, capturing relative relationships between multiple concepts, but not the nuanced context of textual elements within images.
An illustrative example of this challenge can be observed in comic panel generation, where images are often populated with speech and thought bubbles.
Ensuring legible and accurate text generation within such images is crucial for the effectiveness of generative models in this domain, and therefore presents a novel avenue for model improvement.
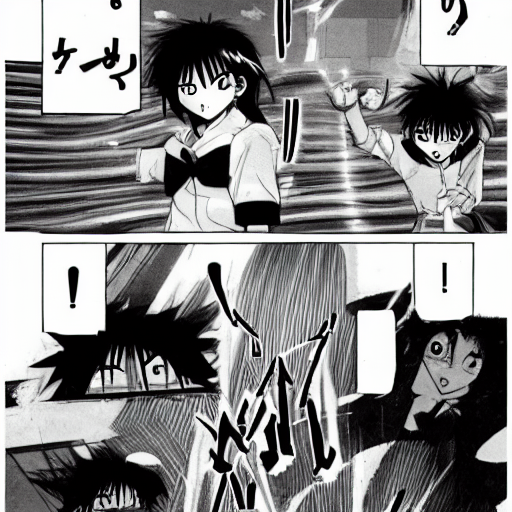
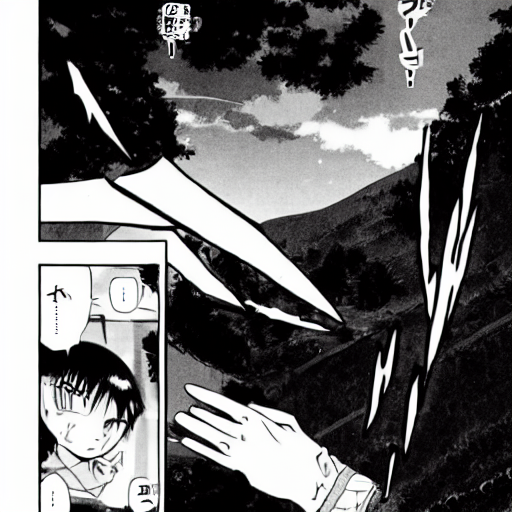
Image 1. Letters blur into each other, and cursive text is illegible.Image 2. Spelling mistakes are often common and obvious.Image 3. Even though the image generated may be realistic, minor spelling errors do occur.Image 4. In languages with complex characters, the characters generated are mostly nonsensical.Image 5. Even in images which have text that stand out (in this case the neon signs), the model still generates gibberish.Image 6. Even simple characters are often not accurately modelled.
Goals and Dataset
Our project aims to enhance the quality of text generated within images by refining the model training process.
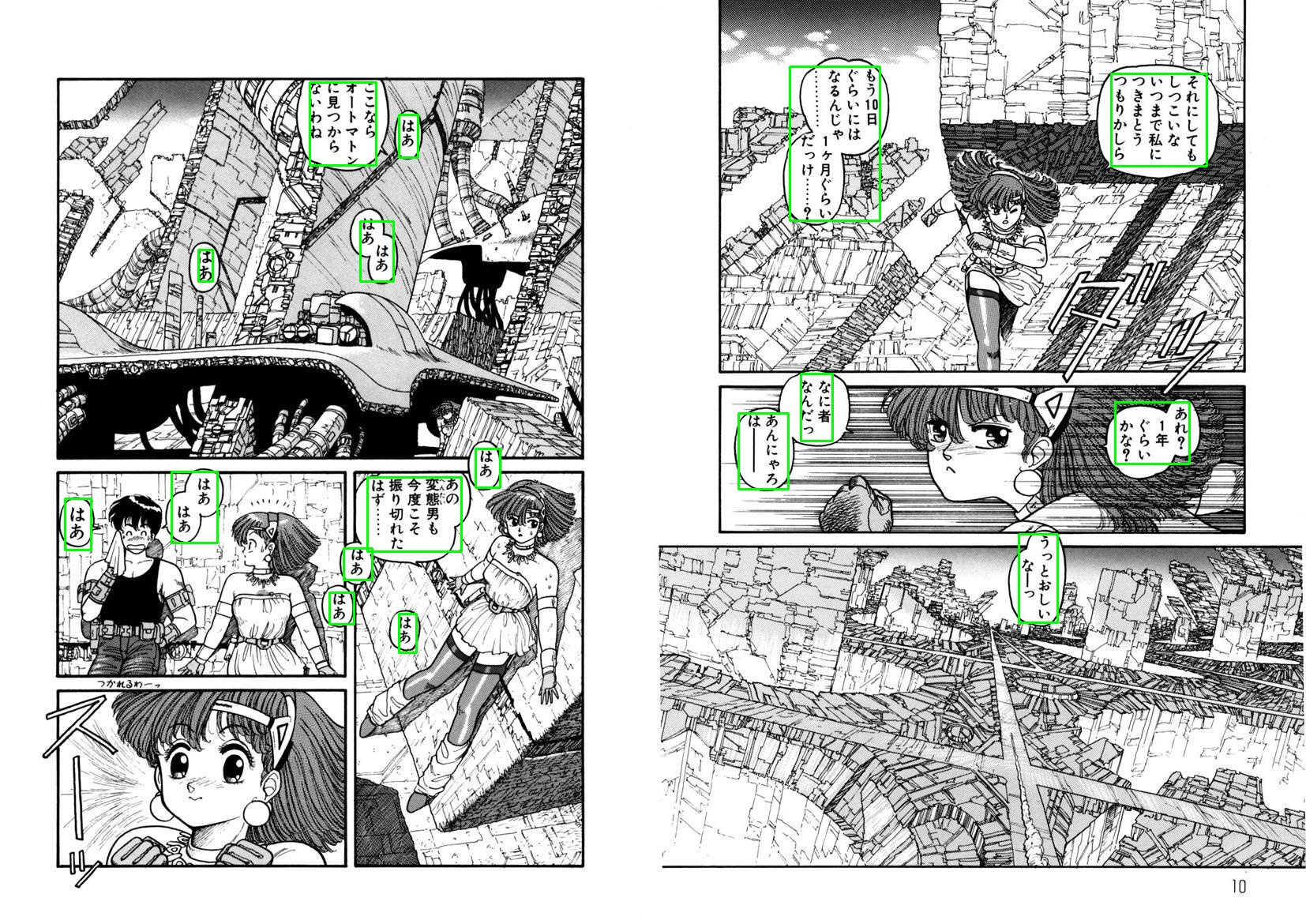
We intend to utilize the Manga109 dataset, which contain manga, a form of Japanese comic panel storytelling method that is typically handdrawn and is littered with text.
The dataset comprises 109 manga collections annotated with various relevant attributes, including text within panels.
Example of a Manga Page in the Manga109 Dataset
The dataset also contains annotations of text instances in each anime page.
Each annotation contains important information including the bounding box as well as the content of each text instance.
Each text instance can be annotated through its bounding box, stored in an accompanying XML file.
Methodology
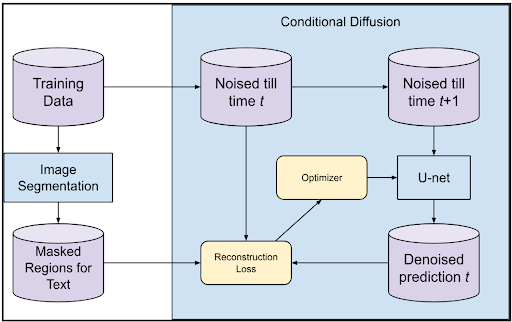
We propose modifying the loss function during model training by adopting a region-specific approach.
Through image segmentation, we isolate the regions within the images that contain text.
This allows a more targeted approach towards learning the representative structures of text, as these regions are information-dense, and the quality of text representations are highly sensitive to fluctuations.
By applying a multiplicative weight to the loss contribution in these regions, we aim to increase the penalty for inaccuracies, thus focusing the denoising process within these critical areas.
Focusing Loss on Text Specific Regions
While using the default rectangular bounding boxes can be a good proxy, we expect to obtain better results with more accurate demarcations of the text regions.
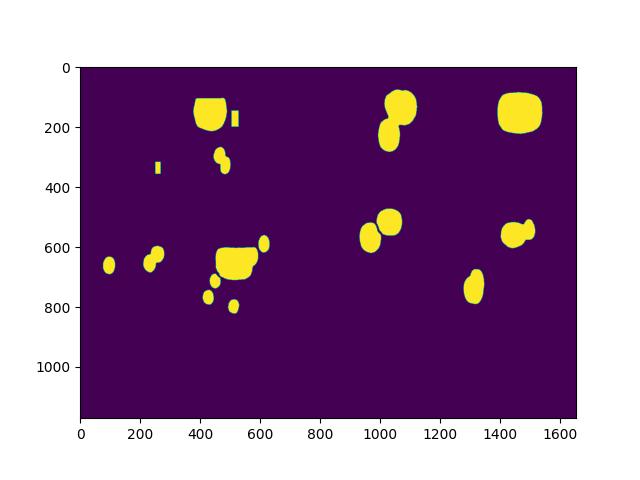
As a result, we use an off-the-shelf image segmentation tool Segment Anything to obtain unlabeled segments of an image.
Since these segments could be of anything, in order to match these segments to actual text bubbles, we perform the following:
For each manga page, we use Segment Anything to generate a list of segment masks, together with their confidence score.
For each provided annotation, we compute the Intersection over Union (IoU) score for each of the masks, and pick the mask with the highest IoU score.
To prevent false matches which can potentially be destructive, we only return segment masks if they are above a threshold confidence score (0.01) and if the ratio of areas is within reasonable bounds (0.75 to 1.33).
Finally, we erode each mask using a simple kernel, to remove the edges of text bubbles which are common in manga, and then dilate it again to capture the boundaries of each word character.
With the following algorithm, we are able to obtain reasonably accurate masks for each manga page.
This approach gives reasonably accurate text bubbles that capture just the text in the image.Upon applying the mask on the original image, we can extract only text from the image, and convert it into a binary mask for later use.
Unconditional Diffusion for Image Generation
With the computation of text masks for each manga image, we finetune a pretrained denoising diffusion probabilistic model (DDPM) on this dataset.
We first finetune a baseline DDPM using a simple reconstruction loss, and then proceed to adapt the loss by increasing the proportion of loss attributed to text regions.
To do so, a simple change was made: F.mse_loss(img, target) was modified to F.mse_loss(img, target) + F.mse_loss(img * mask, target * mask)
We also try out a different type of loss to analyze its effect on image generation. Instead of adding an additional MSE loss component, we instead consider the Binary Cross Entropy (BCE) Loss for the text regions instead.
This could have the effect of distinguishing the background image structure from the foreground text, and produce better results.
Conditional Diffusion for Image Generation
While unconditional manga generation may be interesting, a more practical use of this method would be to guide the diffusion process into generating images that are specified by a conditioning prompt.
Therefore, we also finetune a conditional LDM by passing in a prompt containing the text of choice for the generated manga.
To do so, we used
A manga page containing the text: "(text input)"
as a conditioning prompt, where the image generation task was further simplified by providing the annotation with only the longest sequence length into the prompt.
If no text was present in the manga, the conditioning prompt defaults to
A manga page.
The Problem with Latent Diffusion Models
In an LDM, an encoder-decoder pair is first trained on the dataset of images in order to extract a latent representation of each image.
The noising and denoising process is then performed on the latent vectors, which lead to better performance.
However, this presents a novel problem in our approach, since the diffusion process is now in the latent space rather than in the pixel space.
To overcome this issue, we try two different approaches to augment the loss for regions which contain text.
Approach 1: The Naive Approach
The amplitude of each mask was first increased by a factor of 8, as the Gaussian blur in the next step lowers the amplitude.
A Gaussian blur was then applied to each mask.
The mask was then resized to the size of the latent space and used for loss augmentation, in a similar fashion to the unconditional DDPM model.
Approach 2: A Better Approach
First, mask the image and pass this masked image into the encoder to encode it into latent space.
Activations of high magnitude are likely to correspond to activations that semantically represent textual information, since we only pass in text. Therefore, exponentiate this latent vector.
Use this strictly positive mask as a multiplicative factor to augment our loss in the latent space, i.e., F.mse_loss(img, target) + F.mse_loss(img * mask_latents, target * mask_latents)
When we encountered this problem, we first tried a naive approach towards encoding mask information in the latent space. The rationale behind the naive approach was based on our assumption that each element in the latent vector had a localized receptive field over the original image, thus to mask those parts of the image, we just needed to mask all latent elements that included those parts in their receptive field.
However, the above assumption seemed a little too strong, and after going back to the foundations behind neural networks and thinking intuitively about how they work, we were able to devise a second method that had better grounding and would also hopefully produce better results.
Results
Unconditional Diffusion for Image Generation
The first set of experiments on the DDPM with and without additional masked loss produces fairly reasonable results, although the effect of this loss seems to increase the frequency of text instead.
This seems reasonable, since adding an additional component of loss that just comes from text data could have the effect of increasing the density of text in each image.
Without additional masked loss.With additional masked loss. This seems to have two effects: increase in density of text, as well as the complexity of text generated.
In comparing these two images, we can also see that the complexity of text is increased.
We hypothesize that this is so as without any additional text mask loss, the loss penalty will be relatively smaller for wrong text, and therefore the model learns to compress the characters into simple common ones that are good enough for generation.
We also attempt to augment the loss by using BCELoss, which, while has little improvement to the images generated, does improve overall stability in the training regime.
With additional BCELoss. While there is little improvement, the training loss seems to be more stable.
Conditional Diffusion for Image Generation
For each approach, we generate images based on the following 6 prompts, selected to represent varied complexity. Words that are likely to appear in manga dialogue were chosen.
A manga page
A manga page containing the text: "あ"
A manga page containing the text: "ほら"
A manga page containing the text: "マジかよ"
A manga page containing the text: "今日何する?"
A manga page containing the text: "パンとか食べる?"
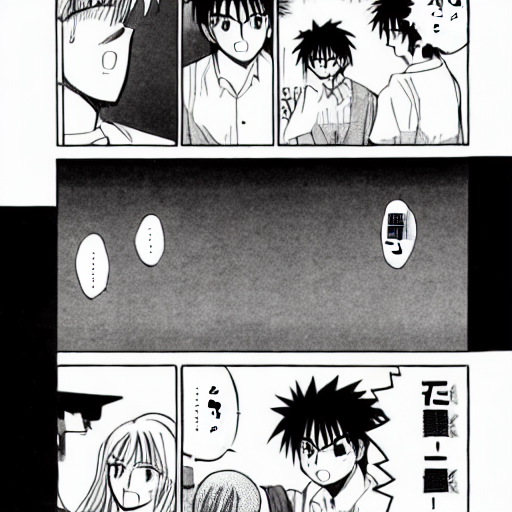
The following images were generated from the LDM without any additional loss augmentation, and can be used as a baseline for comparison. Note that most of the images fail to generate much text, and we get dots ("...") instead. This is expected, since the model page itself mentions "cannot render legible text" as part of its limitations.
Prompt: A manga page Prompt: A manga page containing the text: "あ"Prompt: A manga page containing the text: "ほら"Prompt: A manga page containing the text: "マジかよ"Prompt: A manga page containing the text: "今日何する?"Prompt: A manga page containing the text: "パンとか食べる?"
Approach 1: The Naive Approach
The text generated were mostly not correct and did not correspond to any Japanese text, and were quite deformed. The quality of the text/images here do not seem to be any higher than the baseline above. We concluded that our assumption when designing the naive approach was too strong, and may not have held for our chosen LDM model.
Prompt: A manga page Prompt: A manga page containing the text: "あ"Prompt: A manga page containing the text: "ほら"Prompt: A manga page containing the text: "マジかよ"Prompt: A manga page containing the text: "今日何する?"Prompt: A manga page containing the text: "パンとか食べる?"
Approach 2: A Better Approach
These images were generated by passing the masked image through the encoder, and using the exponents of these activations as a scaling factor to augment the loss function.
Logically, this method makes more sense, since the activations that have high magnitude are likely the ones that correspond to text features.
Prompt: A manga page Prompt: A manga page containing the text: "あ"Prompt: A manga page containing the text: "ほら"Prompt: A manga page containing the text: "マジかよ"Prompt: A manga page containing the text: "今日何する?"Prompt: A manga page containing the text: "パンとか食べる?"
Despite the fact that the text generated does not correspond to the text provided in the prompt, we do see that there are certain words that are correctly generated, and both the quality and quantity of text in the images is significantly higher.
Many of the generated characters have a high degree of accuracy, which seems to suggest that this method works much better than the previous naive approach as well as the baseline.
Finally, we can also compare the training loss curves, to understand the stability of training.
Training Loss without Loss AugmentationTraining Loss with Naive Loss AugmentationTraining Loss with Better Loss Augmentation
While the magnitude of loss is different due to the inherently different number of loss components in training, all training regimes seem to be stable.
Challenges and Conclusion
A considerable challenge at first was the extraction of text from manga.
Although we first considered using text boxes, we soon realized that they left in a lot of additional noise, which could hamper the loss augmentation process.
This is why, in the end, we decided to use a separate image segmentation tool, and developed our own algorithm to produce better text masks.
Another significant challenge that we encountered was how to use the produced text mask information in augmenting the loss in latent space.
This was difficult since the latent space has obscured semantic meaning, and required us to think of new approaches bring the text mask into latent space.
Ultimately, we believe that this methods works well and that it may be in the right direction for training generative LDMs that produce better text.
In conclusion, we believe that this is the right direction for improving the text generation abilities of generative models.
Since these regions are information-dense to begin with, placing higher emphasis on the loss function for these areas will therefore result in better text generation qualities.
Therefore, we believe that future work can consider this as an approach for better image generation.