Method
Recently, Parmar et al. 2024 introduced a method to adapt one-step diffusion models for the unpaired image translation task and use cycle-consistency loss (Zhu et al. 2017). The resulting CycleGAN-Turbo model outperforms existing methods on unpaired image translation. Inspired by these results, we adapt CycleGAN-Turbo to augment off-road driving datasets, where the images are more unstructured and are not paired between the source and target domain.
CycleGAN-Turbo uses SD-Turbo (Sauer et al. 2023) as the backbone, which is a one-step diffusion model distilled from Stable Diffusion. CycleGAN-Turbo turns the text-to-image model into an image translation model by modifying the architecture and training procedure. First, it feeds the conditioning image directly to the diffusion model as input instead of noise. Then, the model backbone is adapted to the conditioning image input by adding LoRA adapters to each module and retraining the first layer of the U-Net. Finally, it introduces Zero-Convs and skip connections between the encoder and decoder to preserve the high-frequency details of the input. We show the figure from Parmar et al. 2024 below to illustrate the CycleGAN-Turbo method.
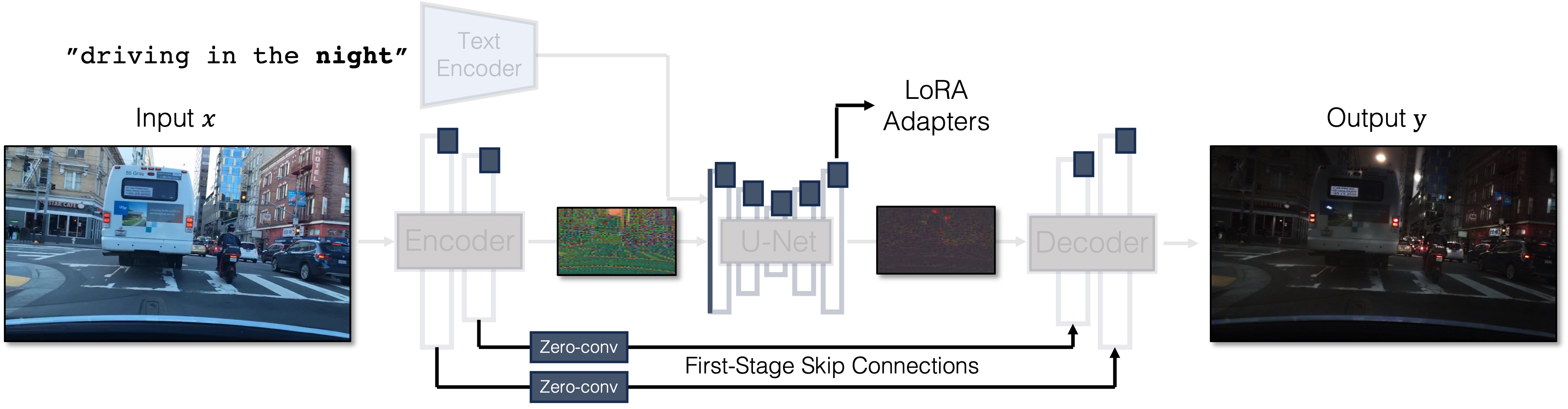
To learn unpaired image translation, CycleGAN-Turbo trains with the following training objective which combines 3 different losses: \[ \arg\min_G \mathcal{L}_{\text{cycle}} + \lambda_{\text{idt}} \mathcal{L}_{\text{idt}} + \lambda_{\text{GAN}} \mathcal{L}_{\text{GAN}} \] where \(\mathcal{L}_{\text{idt}}\) is the identity regularization loss, \(\mathcal{L}_{\text{GAN}}\) is the GAN loss, and \(\lambda_{\text{idt}}\) and \(\lambda_{\text{GAN}}\) are loss weights. \(\mathcal{L}_{\text{cycle}}\) is the cycle-consistency loss, which is defined as \[ \mathcal{L}_{\text{cycle}} = \mathbb{E}_{x}[\mathcal{L}_{\text{rec}} (G(G(x, c_Y), c_X), x)] + \mathbb{E}_{y}[\mathcal{L}_{\text{rec}} (G(G(y, c_X), c_Y), y)] \] where \(\mathcal{L}_{\text{rec}}\) is a combination of the L1 difference and LPIPS, \(G\) is the generator, \(x\) and \(y\) are images from the source and target domains, and \(c_X\) and \(c_Y\) are conditioning images from the source and target domains.
In our project, we first trained CycleGAN-Turbo on our own off-road driving datasets (see the Dataset section below). We use the default training settings and hyperparameters from the CycleGAN-Turbo paper, and train each image translation model for 25,000 steps. We use 4 NVIDIA A6000 GPUs (48GB VRAM per GPU) to train each model. Then, we extend CycleGAN-Turbo to generate off-road driving images by introducing semantic segmentation masks as additional conditioning to specifically preserve the terrain structure in our translations. First, we obtain semantic segmentation masks by prompting OpenSeeD (Zhang et al. 2023), an open-vocabulary semantic segmentation model, for ["ground", "grass", "tree", "vehicle", "building"] classes, then saving the union of the "ground" and "grass" masks as a binary terrain segmentation mask. Then, we experiment with 4 different methods of adding the terrain segmentation mask as conditioning.
1. Masked Cycle Loss: We modify the training objective to increase the cycle loss weight inside the terrain segmentation mask, and decrease the cycle loss weight outside of the mask. This may encourage the model to focus on preserving the terrain structure in the generated images, while allowing other environment appearance factors like the sky, trees, and atmospheric dust to be more freely translated to the target domain. Thus, we modify the cycle-consistency loss definition to become $$\begin{align*} \mathcal{L}_{\text{cycle}} &= \mathbb{E}_{x}[ \lambda_{\text{in_mask}} \mathcal{L}_{\text{rec}} (G(G(x, c_Y), c_X) * m_x, x * m_x)] \\ &+ \mathbb{E}_{x}[ \lambda_{\text{out_mask}} \mathcal{L}_{\text{rec}} (G(G(x, c_Y), c_X) * (1 - m_x), x * (1 - m_x))] \\ &+ \mathbb{E}_{y}[\lambda_{\text{in_mask}} \mathcal{L}_{\text{rec}} (G(G(y, c_X), c_Y) * m_y, y * m_y)] \\ &+ \mathbb{E}_{y}[\lambda_{\text{out_mask}} \mathcal{L}_{\text{rec}} (G(G(y, c_X), c_Y) * (1 - m_y), y * (1 - m_y))] \\ \end{align*}$$ where \(m_x\) is the terrain segmentation mask for image \(x\), \(m_y\) is the terrain segmentation mask for image \(y\), \(\lambda_{\text{in_mask}}\) is the loss weight inside the mask, and \(\lambda_{\text{out_mask}}\) is the loss weight outside the mask. We set \(\lambda_{\text{in_mask}} = 1.0\) and \(\lambda_{\text{out_mask}} = 0.2\) in our experiments. We also tried a masked identity loss where we increase the identity loss weight inside the mask and decrease the identity loss weight outside of the mask, but found that this led to similar results as the masked cycle loss.
2. Mask as an additional input channel: We concatenate the terrain segmentation mask as an additional input channel to the conditioning image, then feed the concatenated image to the U-Net. This method may allow the model to directly see the terrain segmentation mask as input and learn to generate images conditioned on the terrain structure. In order to adapt SD-Turbo to accept the additional input channel, we change the first layer of the U-Net to accept 5 input channels instead of the original 4 while keeping the output size the same, then retrain this modified layer along with the rest of the CycleGAN-Turbo modules. We use the default training settings and hyperparameters from the CycleGAN-Turbo paper.
3. Adding DenseDiffusion during inference: We add the DenseDiffusion (Kim et al. 2023) attention modulation method during inference to guide the generated image's terrain to only appear within the input image's terrain segmentation mask. For example, to perform the Desert to Forest Trail translation, we input a desert image with the prompt "photo of a forest trail" to the trained CycleGAN-Turbo model, then increase the attention scores in the region corresponding to the "forest trail" tokens and the desert image's terrain segmentation mask, while decreasing the attention scores outside of this region. We use DenseDiffusion's default hyperparameters, except we multiply the scalar $\lambda_t$ by 0.25 for the Desert to Forest Trail translation and 0.75 for the Smooth Dirt Trail to Forest Trail translation.
4. Adding a new Mask IoU Loss Term: We modify the training objective to include a new Mask IoU loss term in order to encourage the generated image to have a high Intersection over Union (IoU, also known as Jaccard Score) with the input image's terrain segmentation mask. Thus, the new training objective becomes $$\begin{align*} \arg\min_G \mathcal{L}_{\text{cycle}} + \lambda_{\text{idt}} \mathcal{L}_{\text{idt}} + \lambda_{\text{GAN}} \mathcal{L}_{\text{GAN}} + \lambda_{\text{mask}} \mathcal{L}_{\text{mask}} \end{align*}$$ where \(\mathcal{L}_{\text{mask}}\) is the Mask IoU loss term, and \(\lambda_{\text{mask}}\) is the loss weight. The Mask IoU loss term is defined as $$\begin{align*} \mathcal{L}_{\text{mask}} &= 1 - \text{IoU}[m_y, M(G(y, c_X))] + 1 - \text{IoU}[m_x, M(G(x, c_Y))] \\ \end{align*}$$ where \(M\) is the OpenSeeD model to predict the terrain segmentation mask, and \(\text{IoU}[a, b]\) is the Intersection over Union between masks \(a\) and \(b\). We set \(\lambda_{\text{mask}} = 0.25 \) in our experiments.
Due to time constraints, we only trained this method on ~17,000 steps for each translation and did not tune the hyperparameters to balance the Mask IoU Loss term with the existing losses.
Dataset
For Datasets, we collected five distinct domain datasets from three off-road driving environments:
- Desert: a dataset of 933 images sampled from a YouTube video in the desert.
- Forest Trail: a dataset of 513 images sampled from RUGD with a trail within the forest.
- Forest: a dataset of 753 images sampled from RUGD inside the forest.
- Parking Lot: a dataset of 306 images sampled from RUGD of a parting lot.
- Smooth Dirt Trail: a dataset of 999 images sampled from TartanDrive on a smooth trail without vegetation.

Based on these 5 domain datasets, we performed the following three domain transfers:
- Desert - Forest Trail translation
- Smooth Dirt Trail - Forest Trail translation
- Forest - Parking Lot translation

Baselines
Since we are performing unpaired translation in this setting, we are only comparing our method with the ones that doesn't require paired training data to perform translation. One line of method is the prompt-based image editing methods, such as SDXL-Turbo image-to-image generation and InstructPix2Pix (Brooks et al. 2023).
 We tested SDXL-Turbo image-to-image translation, which is based on SDEdit (Meng et al. 2021) where the latent is initialized
through
adding noise to the input image and then performing the denoising steps from that.
We tested SDXL-Turbo image-to-image translation, which is based on SDEdit (Meng et al. 2021) where the latent is initialized
through
adding noise to the input image and then performing the denoising steps from that.
As shown in the figures, although directly running inference on image-to-image generation models can preserve the structure of the input image well, the transformed images look pretty different than the desired target domain. This is because the model has not seen the specific domains that we expect it to transfer images into, and therefore the distribution gap harms the performance.
Our Results
Evaluation Metrics
We evaluate our image translations using 3 metrics. Following the CycleGAN-Turbo paper, we use FID and DINO Structure distance. We report all DINO Structure scores multiplied by 100. We then define an additional metric, “Ground” semantic segmentation IoU, to specifically measure how well the translation preserves the terrain's structure To calculate this, we prompt the open vocabulary semantic segmentation model OpenSeeD (Zhang et al. 2023) for “ground, "grass", "tree", "vehicle", & "building" segmentations, then use the union of “ground” and "grass" as the final “Ground” semantic segmentation mask.
Quantitative Results
| Method | Smooth Dirt Trail → Forest Trail | Forest Trail → Smooth Dirt Trail | ||||
|---|---|---|---|---|---|---|
| FID ↓ | DINO Struct. ↓ | "Ground" IoU ↑ | FID ↓ | DINO Struct. ↓ | "Ground" IoU ↑ | |
| CycleGAN-Turbo | 126.3 | 4.9 | 0.782 | 103.2 | 5.4 | 0.779 |
| CycleGAN-Turbo + Mask IoU Loss | 82.67 | 5.4 | 0.763 | 79.78 | 5.4 | 0.769 |
| CycleGAN-Turbo + Masked Cycle Loss | 88.8 | 5.3 | 0.802 | 70.9 | 6.2 | 0.769 |
| CycleGAN-Turbo + Mask Input Channel | 80.97 | 5.0 | 0.794 | 73.57 | 6.3 | 0.781 |
| CycleGAN-Turbo + DenseDiffusion | 170.2 | 3.5 | 0.947 | 166.7 | 3.0 | 0.892 |
| SDXL-Turbo Img2Img | 249.7 | 4.9 | 0.951 | 179.9 | 5.0 | 0.940 |
| Method | Desert → Forest Trail | Forest Trail → Desert | ||||
|---|---|---|---|---|---|---|
| FID ↓ | DINO Struct. ↓ | "Ground" IoU ↑ | FID ↓ | DINO Struct. ↓ | "Ground" IoU ↑ | |
| CycleGAN-Turbo | 143.1 | 4.7 | 0.791 | 133.0 | 6.3 | 0.894 |
| CycleGAN-Turbo + Mask IoU Loss | 122.6 | 4.6 | 0.794 | 120.3 | 5.0 | 0.878 |
| CycleGAN-Turbo + Masked Cycle Loss | 124.3 | 6.6 | 0.758 | 155.0 | 7.5 | 0.857 |
| CycleGAN-Turbo + Mask Input Channel | 113.6 | 4.5 | 0.780 | 105.6 | 4.9 | 0.884 |
| CycleGAN-Turbo + DenseDiffusion | 157.1 | 4.7 | 0.796 | 146.5 | 4.4 | 0.880 |
| SDXL-Turbo Img2Img | 306.7 | 4.9 | 0.781 | 268.2 | 5.0 | 0.842 |
Overall, our extensions of CycleGAN-Turbo show improvements compared to the original CycleGAN-Turbo method and SDXL-Turbo Img2Img. However, in terms of quantitative results, no single extension performed the best across all metrics. Next, we show visual results, where differences between methods are more apparent.
Qualitative Results
Masked cycle loss


We first implemented the masked cycle loss method, using masks to weight the reconstruction loss to incorporate the mask information into the training process. The results are shown in the figure above. Generally, the model follows the structure of the input image. However, since it's not penalizing generation outside the region, the generated image can leave out important components outside the mask or create additional terrain that was not present in the input image. For example, in the first column of Desert-to-Forest Trail, the car is not preserved as it's not inside the masked area. Moreover, we still observe some changes in the structure of images (the first and third columns in Smooth Dirt-to-Forest Trail). This suggests that only increasing the penalization weight within the mask area is not enough. Additionally, the generated image sometimes isn't blended that well since we have different losses for different regions.

Mask Input Channel


We also implemented the mask input channel as it is another way to incorporate mask information into the generation process. The output image's terrain does not match the shape of the input image's terrain. This is because in this method, we are only providing the mask as additional information to the model and we are not adding any guidance as to how the model learns, i.e. the loss function was not modified to incorporate the mask. Thus, objects in the input image that are outside of the mask are also not preserved well in the output image and look very transparent, similar to the results of masked cycle loss.

Mask IoU Loss


Based on our observations on the previous two methods, we introduce the mask IoU loss between input and generated image for a more direct way to enforce semantic and structure preservation. Results show that the objects (for example, the vehicles in Desert-to-Forest translation) are preserved and blended into the scene well in the above figure and are no longer transparent. However, the model is still not able to preserve distant objects: for example, the vehicle in the first column of Forest Trail-to-Smooth Dirt translation disappears in the generated image.

The generated image at the early stage of training is able to preserve the overall structure of forest terrain and does not stretch it like other methods, demonstrating that the model is able to learn the preservation of terrain structure with the IoU loss. However, as training continues, it loses this ability as shown in the above figure. We believe this can be mitigated by increasing the weight (currently set to 0.25) of the IoU loss to constrain the generation.
Dense Diffusion


We also experimented with modifying the attention maps during inference time using DenseDiffusion. As the attention modulation increases, the generated image looks more like the input image and source domain, instead of directly changing the terrain region's shape while staying in the target domain. The generated images also have artifacts and do not look photorealistic. This may be because DenseDiffusion is originally formulated for using multi-step diffusion to guide the layout of the output image, while CycleGAN-Turbo only has one step to produce the output with modified layout.
General Observations

In general, the CycleGAN-Turbo models seem to be learning the input image terrain's texture and generating it again in the output image. This may be because the training objective includes the image reconstruction loss (LPIPS + L1 distance) which encourages the preservation of the input image terrain's texture.
