Overview
This assignment includes two parts: in the first part, we will implement a specific type of GAN designed to process images, called a Deep Convolutional GAN (DCGAN). We will train the DCGAN to generate grumpy cats from samples of random noise. In the second part, we will implement a more complex GAN architecture called CycleGAN for the task of image-to-image translation. We will train the CycleGAN to convert between different types of two kinds of cats (Grumpy and Russian Blue).
Part 1: DCGAN
The model for DCGAN we used was identical to what the writeup describes: the discriminator is composed of convolutionals while the generator is composed of transposed convolutions.
The exact architectures are displayed below.
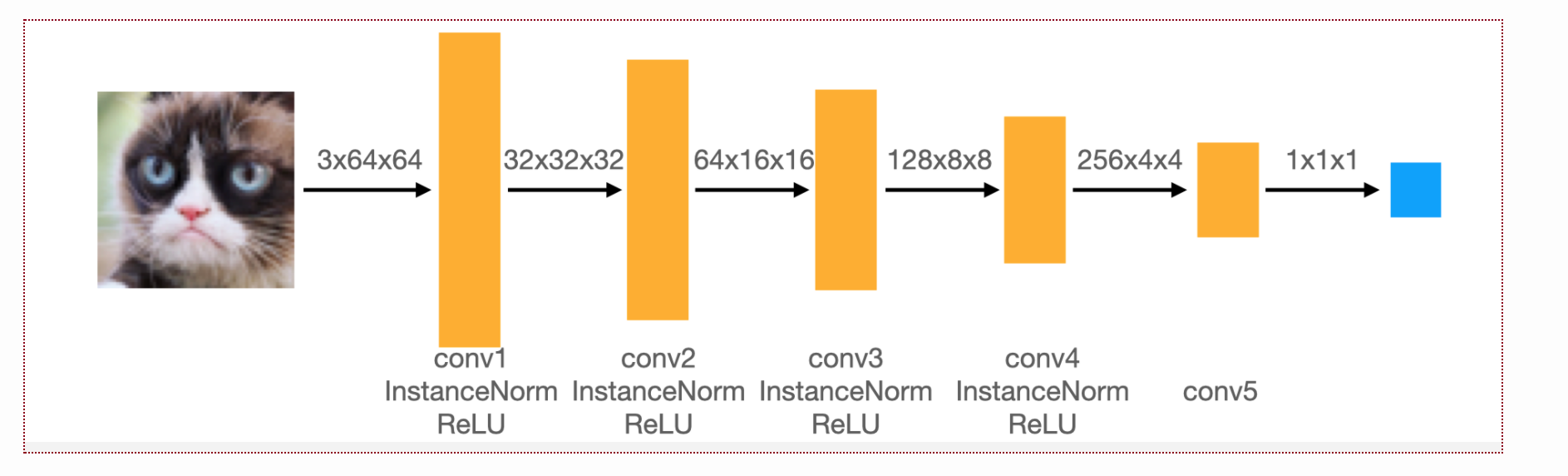
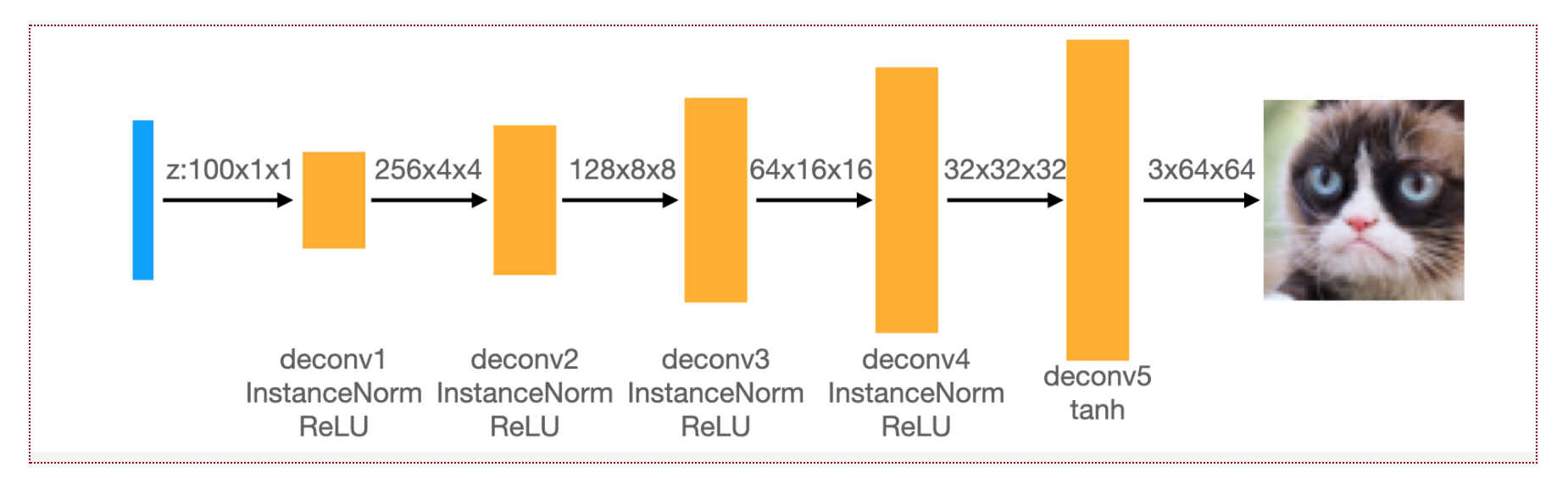 When determining what padding to use, note that our kernel size is 4, our stride length is 2, and our dilation is 0. According to the Pytorch documentation, we must have
When determining what padding to use, note that our kernel size is 4, our stride length is 2, and our dilation is 0. According to the Pytorch documentation, we must have
 Thus, the padding for the first four convolution layers in the discriminator will be 1 while the padding for the last layer will be 0.
Similarly, for the generator, the padding in the first deconvolution layer is 0 while the padding for the remaining 4 layers is 1.
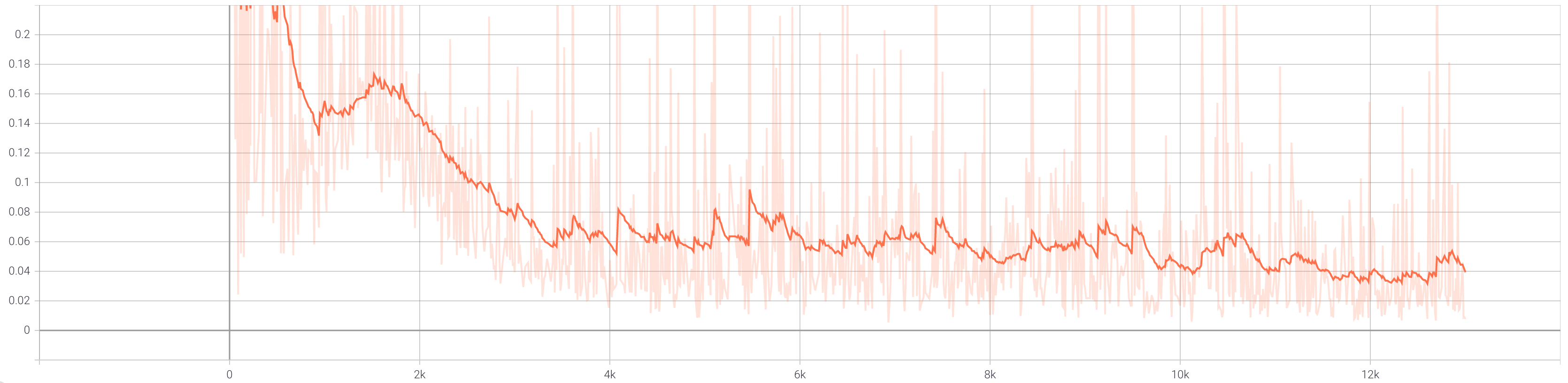
During training, we also use data augmentation in the form of random cropping and random horizontal flips. First, we show the total loss curves for the discriminator and generator when training without data augmentation.
Thus, the padding for the first four convolution layers in the discriminator will be 1 while the padding for the last layer will be 0.
Similarly, for the generator, the padding in the first deconvolution layer is 0 while the padding for the remaining 4 layers is 1.
During training, we also use data augmentation in the form of random cropping and random horizontal flips. First, we show the total loss curves for the discriminator and generator when training without data augmentation.
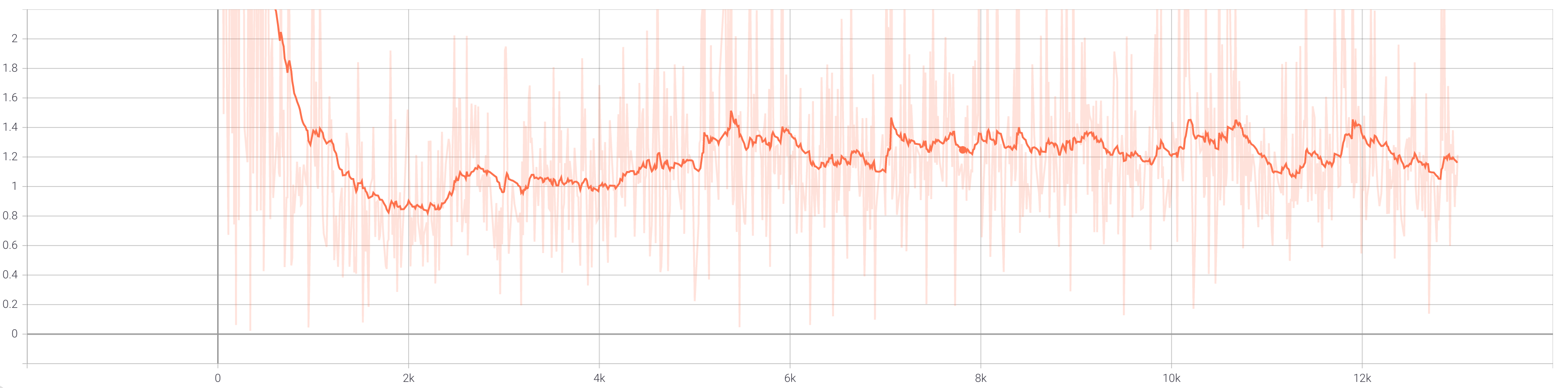 When we train with augmentation, the total loss curves for the discriminator and generator appear as follows.
When we train with augmentation, the total loss curves for the discriminator and generator appear as follows.
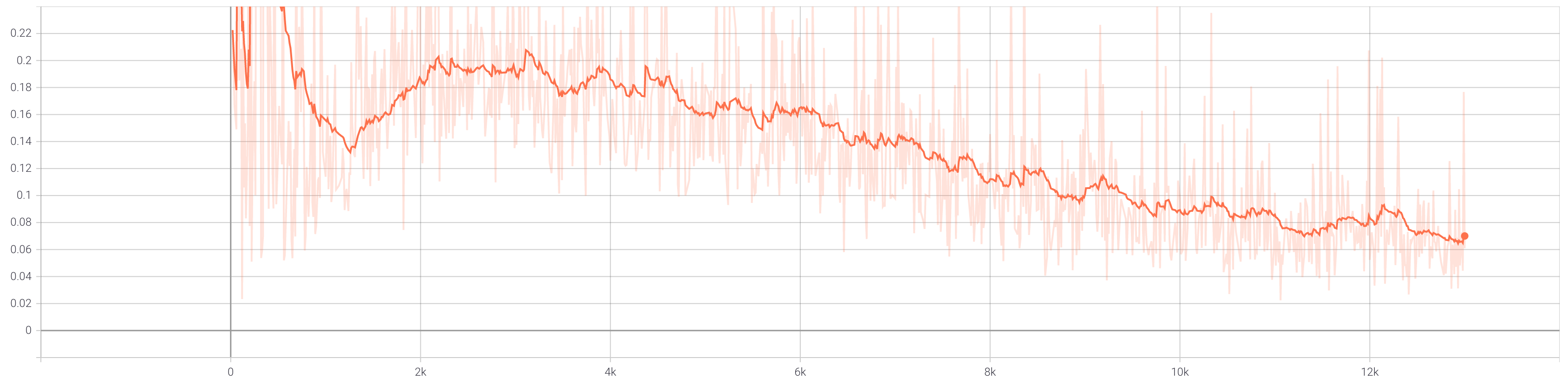
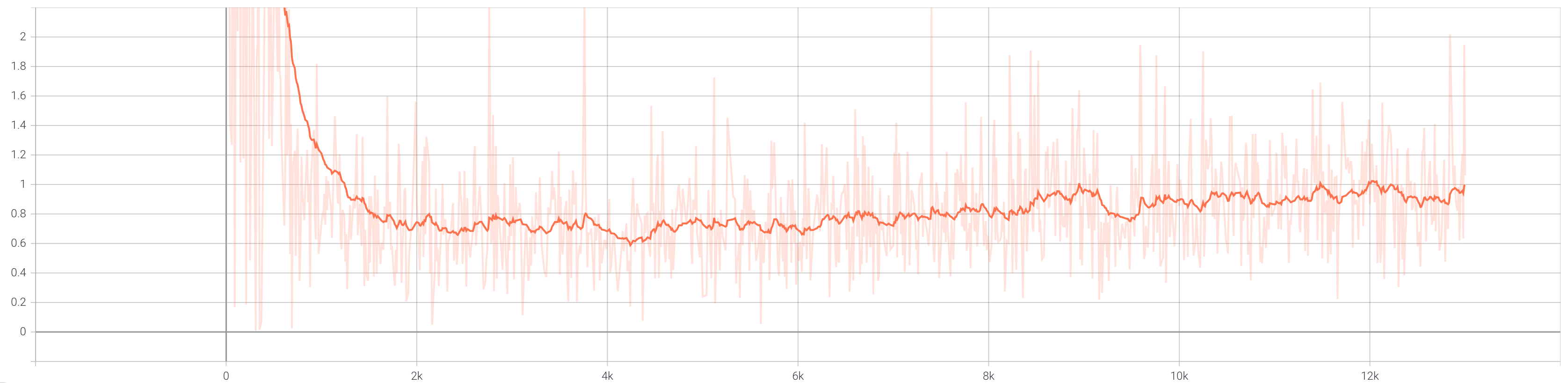 In both cases, we see that the total loss for the generator hits a minimum between [0.6, 0.8] around 2000 iterations in and then
steadily increases. Meanwhile, both discriminator graphs show the loss generally decreasing to around [0.05, 0.1]. These graphs
indicate that the discriminator is improving faster than the generator, but the model has not collapsed and is still learning. A nice
visualization of how the samples evolve over training is presented below.
In both cases, we see that the total loss for the generator hits a minimum between [0.6, 0.8] around 2000 iterations in and then
steadily increases. Meanwhile, both discriminator graphs show the loss generally decreasing to around [0.05, 0.1]. These graphs
indicate that the discriminator is improving faster than the generator, but the model has not collapsed and is still learning. A nice
visualization of how the samples evolve over training is presented below.
 Overall, the results are satisfactory as we see the shape and features of the generated grumpy cats increase in clarity as training
progresses. Notably, in the beginning of training, the generated images are quite pixelated and lack sharp features. We see
these features (shape of mouth, color of eyes, coloring of fur) begin to develop near the middle of training. The end result is pretty
impressive although it is low-resolution and has some small artifacts.
Overall, the results are satisfactory as we see the shape and features of the generated grumpy cats increase in clarity as training
progresses. Notably, in the beginning of training, the generated images are quite pixelated and lack sharp features. We see
these features (shape of mouth, color of eyes, coloring of fur) begin to develop near the middle of training. The end result is pretty
impressive although it is low-resolution and has some small artifacts.
Part 2: CycleGAN
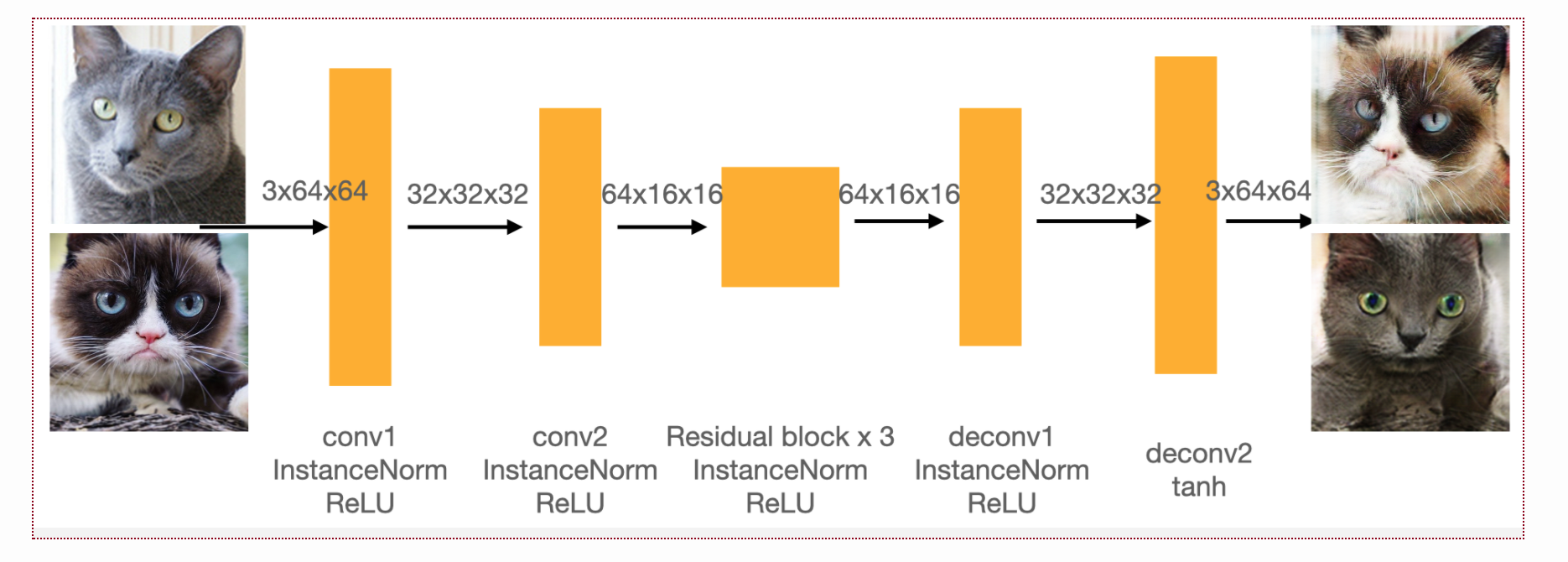
The model for CycleGAN is slightly different from DCGAN. Specifically, the architecture for the generator changes as it's
mapping images to images instead of noise to images. The exact architecture is shown below.
 During training, we also use data augmentation, but there are some differences compared to DCGAN. We update the generator twice as fast as the
discriminator, and we also introduce the concept of the cycle consistency loss.
During training, we also use data augmentation, but there are some differences compared to DCGAN. We update the generator twice as fast as the
discriminator, and we also introduce the concept of the cycle consistency loss.
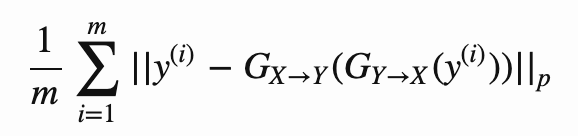 This constrains the model and enforces the idea that the composition of the two generators should act as an identity operator. We implement
this using an L1 loss function with the lambda hyperparameter set to 10. First, we compare the output of the model early in training
when we don't use the consistency loss and when we do. Without it, our initial image to image translation at iteration 600 is shown below from
Russian Blue to Grumpy and vice versa.
This constrains the model and enforces the idea that the composition of the two generators should act as an identity operator. We implement
this using an L1 loss function with the lambda hyperparameter set to 10. First, we compare the output of the model early in training
when we don't use the consistency loss and when we do. Without it, our initial image to image translation at iteration 600 is shown below from
Russian Blue to Grumpy and vice versa.

 When we do use cycle consistency, at iteration 600, the results are shown below.
When we do use cycle consistency, at iteration 600, the results are shown below.

 There's a noticeable improvement for the Russian Blue to Grumpy translation. There are less artifacts around the edges and certain features such
as the color of the eyes are much more apparent. The other direction doesn't appear to be significantly different.
The general imbalance in results is likely due to the larger number of Grumpy cat pictures than Russian Blue cat pictures.
Now, we present the results
during training (with and without cycle consistency) over 10000 iterations. Without cycle consistency, the results evolve as follows.
There's a noticeable improvement for the Russian Blue to Grumpy translation. There are less artifacts around the edges and certain features such
as the color of the eyes are much more apparent. The other direction doesn't appear to be significantly different.
The general imbalance in results is likely due to the larger number of Grumpy cat pictures than Russian Blue cat pictures.
Now, we present the results
during training (with and without cycle consistency) over 10000 iterations. Without cycle consistency, the results evolve as follows.

 Now, the results below are when we do use cycle consistency.
Now, the results below are when we do use cycle consistency.

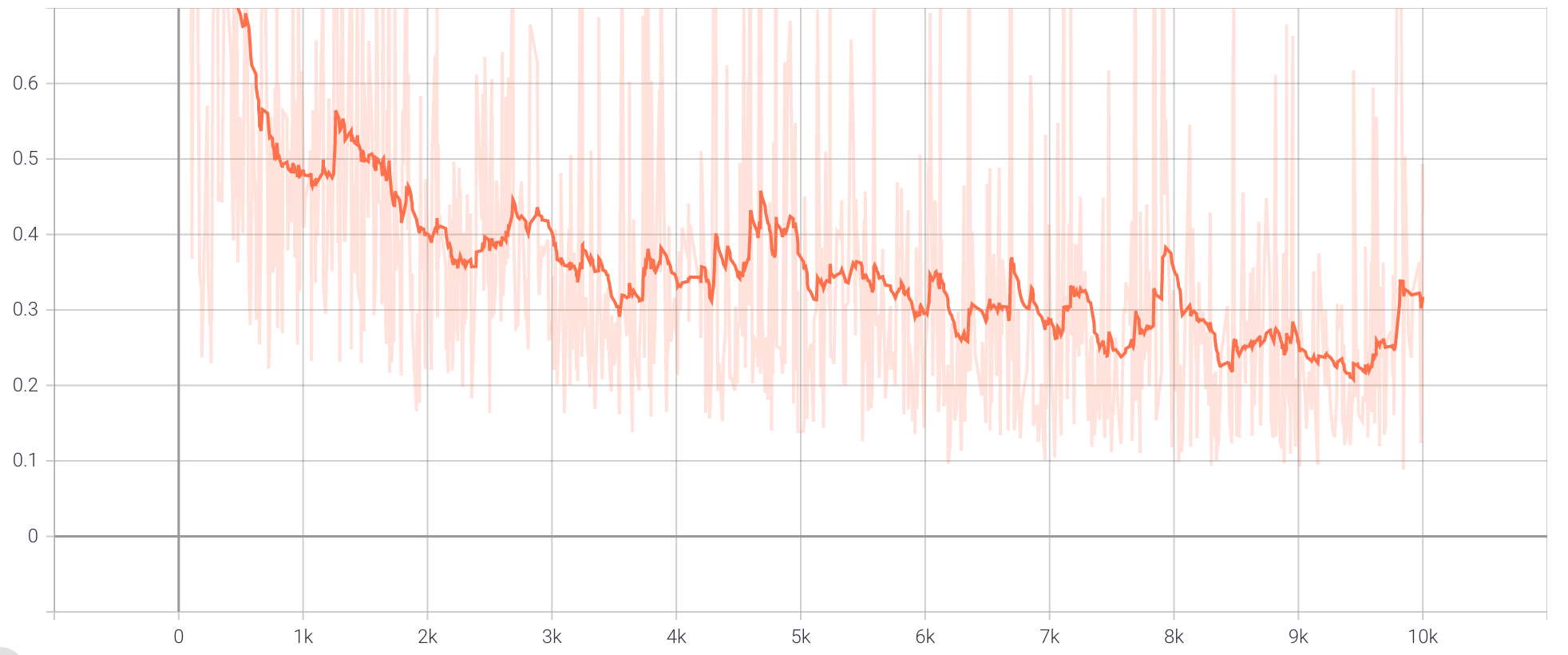
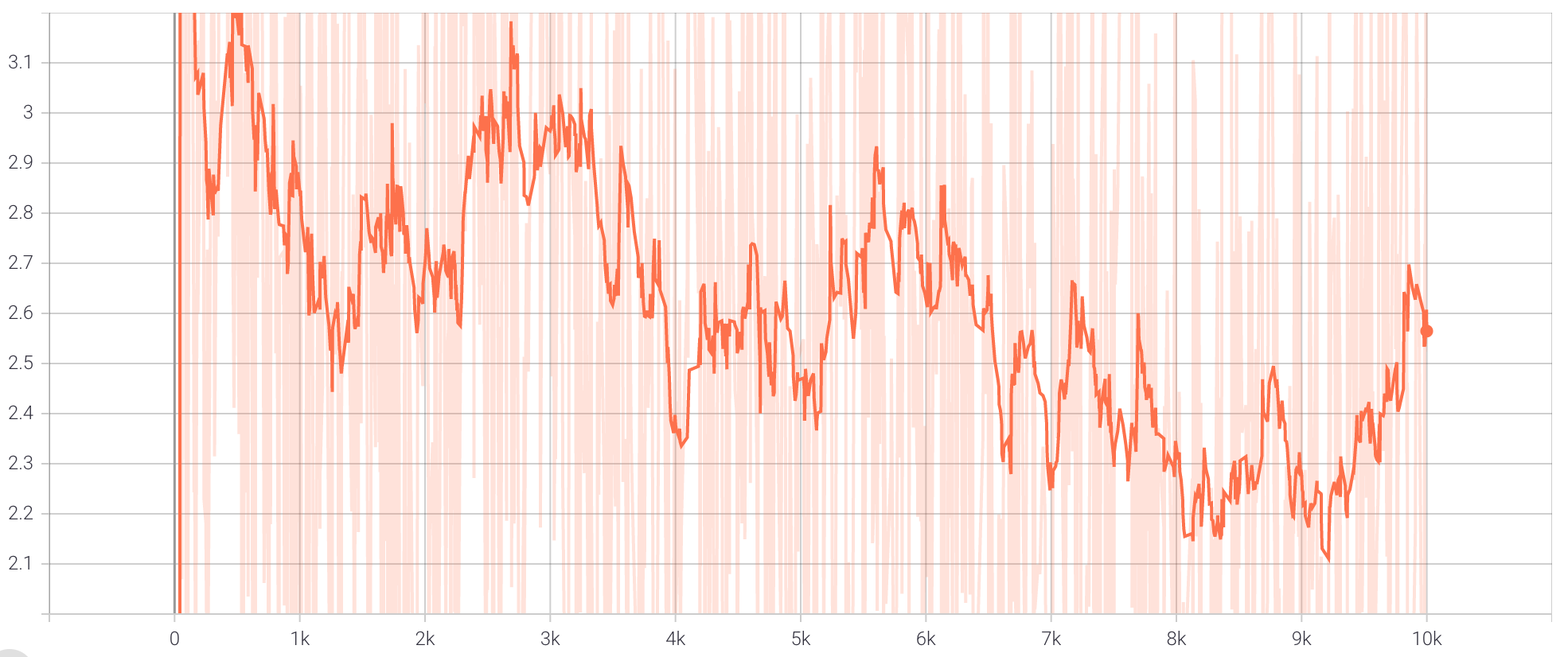
 For comparison, we also provide the loss graphs for discriminator and generator in both cases. The loss graphs without cycle consistency
are shown below.
For comparison, we also provide the loss graphs for discriminator and generator in both cases. The loss graphs without cycle consistency
are shown below.
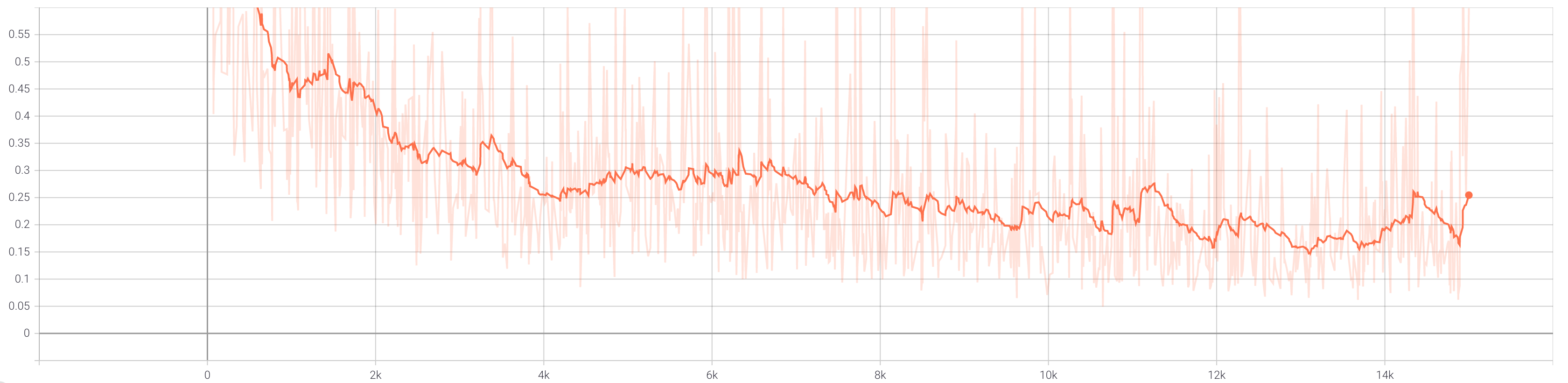
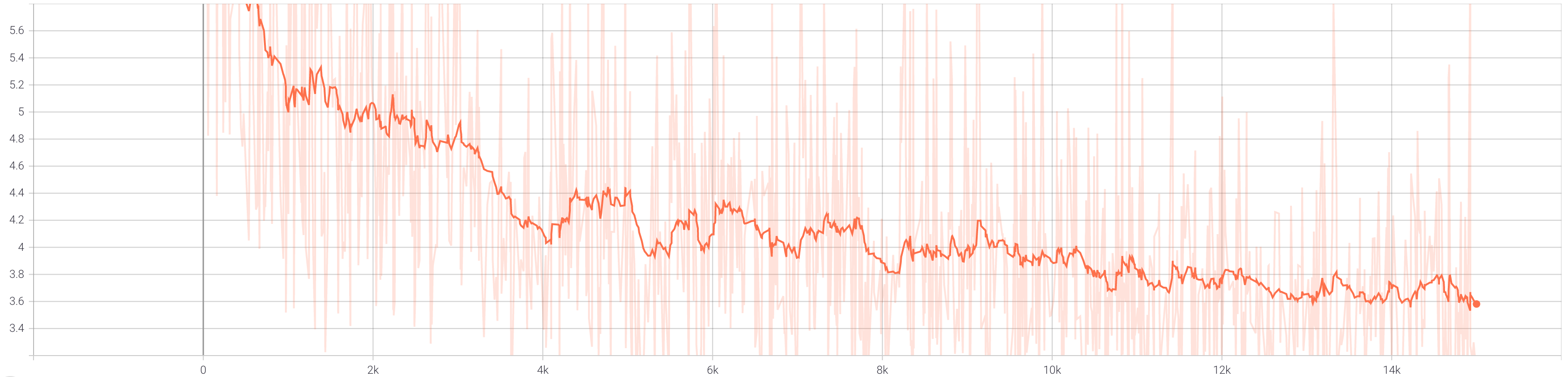
 When we add cycle consistency, the loss graphs are different.
When we add cycle consistency, the loss graphs are different.
 While it's not immediately obvious, using cycle consistency does improve the results throughout training.
The biggest improvement comes from the development of the features around and near the eyes.
The sharpness, color, and features within the eyes are all improved when we use cycle consistency.
Additionally, without it, there's an increase in artifacts such as a grid-like pattern and red occlusions in the generated output for iteration 10000.
Finally, the general diversity of the facial shape and
background seems diminished when we don't use cycle consistency.
While it's not immediately obvious, using cycle consistency does improve the results throughout training.
The biggest improvement comes from the development of the features around and near the eyes.
The sharpness, color, and features within the eyes are all improved when we use cycle consistency.
Additionally, without it, there's an increase in artifacts such as a grid-like pattern and red occlusions in the generated output for iteration 10000.
Finally, the general diversity of the facial shape and
background seems diminished when we don't use cycle consistency.
Bells & Whistles: PatchGAN
We also implement PatchGAN by removing the last 2 layers of the discriminator and averaging when computing the losses during training. The results
are quite impressive! We see that PatchGAN preserves local features very well compared to normal CycleGAN.

