Overview
In this assignment, you will implement neural style transfer which resembles specific content in a certain artistic style. For example, generate cat images in Ukiyo-e style. The algorithm takes in a content image, a style image, and another input image. The input image is optimized to match the previous two target images in content and style distance space.
Part 1: Content Reconstruction
In order to do content reconstruction from white noise, we optimize the pixel values of the input image (noise) so that the content loss is minimized.
If we extract features of our input image and some content image we wish to reconstruct at various layers of a pre-trained VGG-19 network,
content loss is defined as the L2-distance between these features across layers. The VGG-19 architecture is shown below.
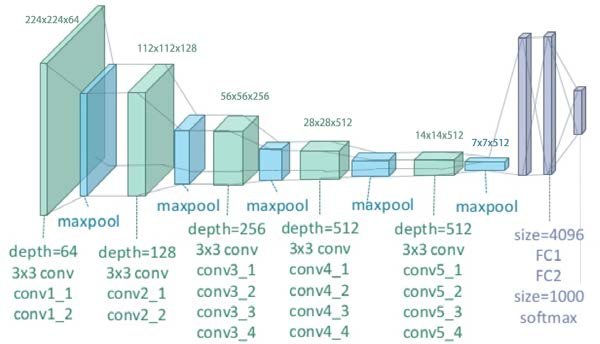 We use the quasi-newton optimizer LBFGS for 300 steps and default parameters in order to optimize the
input image. The actual implementation of this largely follows the provided starter code, although all images are resized to be of size 256 x 256.
Now, we first look at the effect of optimizing content loss at five different layers: conv1, conv4, conv7, conv10, conv13. The convolutional layers are
enumerated according to the order they appear in the model shown above.
We use the quasi-newton optimizer LBFGS for 300 steps and default parameters in order to optimize the
input image. The actual implementation of this largely follows the provided starter code, although all images are resized to be of size 256 x 256.
Now, we first look at the effect of optimizing content loss at five different layers: conv1, conv4, conv7, conv10, conv13. The convolutional layers are
enumerated according to the order they appear in the model shown above.
 Overall, we see that reconstruction is nearly perfect (aside from some lighting differences) for the earlier convolutional layers like conv1 and conv4
but quickly degrades for the later layers. This is expected as they will learn higher level features at the expense of pixel-level information.
The strong content reconstruction for the conv4 layer is an encouraging sign as it suggests we can simultaneously optimize
the style to achieve neural style transfer. We also show results for content reconstruction on our favorite results from above across different runs to show the effect of input initialization.
Overall, we see that reconstruction is nearly perfect (aside from some lighting differences) for the earlier convolutional layers like conv1 and conv4
but quickly degrades for the later layers. This is expected as they will learn higher level features at the expense of pixel-level information.
The strong content reconstruction for the conv4 layer is an encouraging sign as it suggests we can simultaneously optimize
the style to achieve neural style transfer. We also show results for content reconstruction on our favorite results from above across different runs to show the effect of input initialization.
 While only 2 distinct runs are displayed here, the reconstructions were almost always identical to each other across many runs, independent of initialization. As
we noted before, the content is quite similar to the source image apart from some slight blurriness. Very rarely, the output image would be malformed and resemble
noise. This was likely a result of LBFGS converging to a suboptimal, local minima as the loss would stop changing early on (~15-30 steps) during training. Performing
the optimization with respect to a lower resolution (256 x 256 vs 512 x 512 for example) helped avoid this.
While only 2 distinct runs are displayed here, the reconstructions were almost always identical to each other across many runs, independent of initialization. As
we noted before, the content is quite similar to the source image apart from some slight blurriness. Very rarely, the output image would be malformed and resemble
noise. This was likely a result of LBFGS converging to a suboptimal, local minima as the loss would stop changing early on (~15-30 steps) during training. Performing
the optimization with respect to a lower resolution (256 x 256 vs 512 x 512 for example) helped avoid this.
Part 2: Texture Synthesis
In order to do texture synthesis from white noise, we optimize the pixel values of the input image (noise) so that the style loss is minimized.
If we extract features of our input image and some style image we wish to mimic at various layers of a pre-trained VGG-19 network,
style loss is defined as the L2-distance between the Gram matrices of these features across layers. Again, we use LBFGS for 300 steps and default parameters in order to optimize the
input image. The actual implementation also follows the provided starter code, and all images are resized to be of size 256 x 256. Below, we look at the effect
of optimizing style loss using 5 different combinations of layers: [conv1], [conv1 - conv3], [conv1 - conv5], [conv6 - conv10], [conv11 - conv15].
 Similar to content reconstruction, we see that with texture synthesis, the output becomes much more noisy as the set of layers we're optimizing over
shifts from earlier to later. The combination of [conv11 - conv15] is difficult to distinguish across all three style images. Visually, using [conv1 - conv5]
seems to provide the best balance of preserving high-level details like colors and shapes with lower-level details like line structure. We also show
results for texture synthesis across different runs to show the effect of input initialization.
Similar to content reconstruction, we see that with texture synthesis, the output becomes much more noisy as the set of layers we're optimizing over
shifts from earlier to later. The combination of [conv11 - conv15] is difficult to distinguish across all three style images. Visually, using [conv1 - conv5]
seems to provide the best balance of preserving high-level details like colors and shapes with lower-level details like line structure. We also show
results for texture synthesis across different runs to show the effect of input initialization.
 Like content reconstruction, the results are quite similar across various runs, although not identical. The general color scheme, patterns, and lines all match up nicely across
each row with the style image. Unlike content reconstruction, there weren't any issues with the optimizer for texture
synthesis getting stuck in obviously wrong local optima. In some sense, texture synthesis is easier when initializing from noise than content reconstruction as extremely
local, pixel-level details are less important.
Like content reconstruction, the results are quite similar across various runs, although not identical. The general color scheme, patterns, and lines all match up nicely across
each row with the style image. Unlike content reconstruction, there weren't any issues with the optimizer for texture
synthesis getting stuck in obviously wrong local optima. In some sense, texture synthesis is easier when initializing from noise than content reconstruction as extremely
local, pixel-level details are less important.
Part 3: Style Transfer
Finally, we are ready to combine content reconstruction and texture synthesis to perform neural style transfer. Implementation-wise, our code follows the starter code
closely. We normalize the Gram matrix when computing style loss, use a content weight of 1 and a style weight of 1000000, default parameters for LBFGS, and optimize over
conv4 for content loss and [conv1 - conv5] for style loss. We showcase a table of results below.
 The outputs on a variety of content and style images are really impressive! We also compare the results of initializing from the content image versus initializing from noise.
The outputs on a variety of content and style images are really impressive! We also compare the results of initializing from the content image versus initializing from noise.
 The runtimes for both take around 19 seconds if we resize our input, content, and style images to size 256 x 256. One notable difference is that for random noise initialization,
the color scheme is significantly muted and less diverse compared to content image initialization. Naturally, we'd expect content image initialization to require less "help" so
we'd expect better results compared to random noise depending on which content layers we optimize over. Regardless, both results are still quite good!
Finally, we show a selection of some of our favorite results featuring my cat Mimi as well as a grumpy cat picture from the previous assignment.
The runtimes for both take around 19 seconds if we resize our input, content, and style images to size 256 x 256. One notable difference is that for random noise initialization,
the color scheme is significantly muted and less diverse compared to content image initialization. Naturally, we'd expect content image initialization to require less "help" so
we'd expect better results compared to random noise depending on which content layers we optimize over. Regardless, both results are still quite good!
Finally, we show a selection of some of our favorite results featuring my cat Mimi as well as a grumpy cat picture from the previous assignment.
