16-889: Learning for 3D Vision
Assignment 2
Adnan Ahmad (adnana)

1.1 Fitting a Voxel Grid
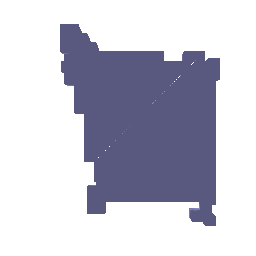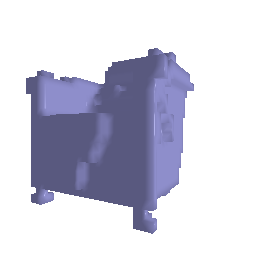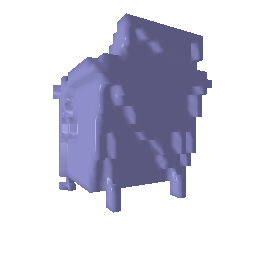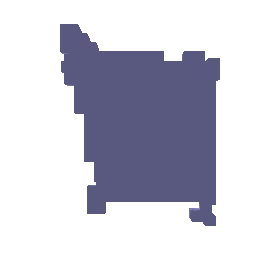
1.2 Fitting a Point Cloud
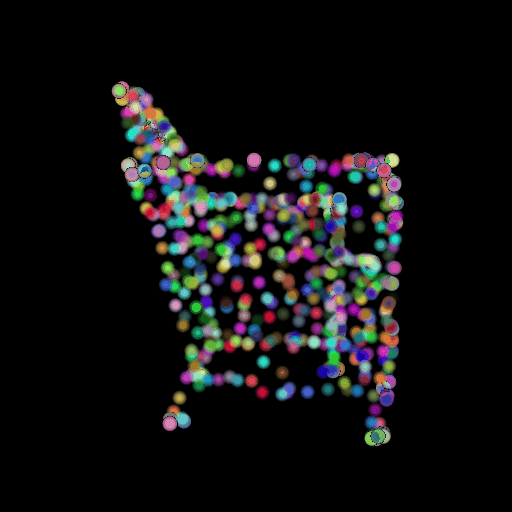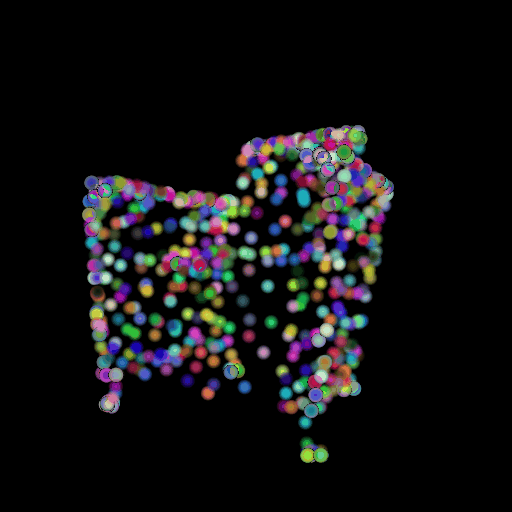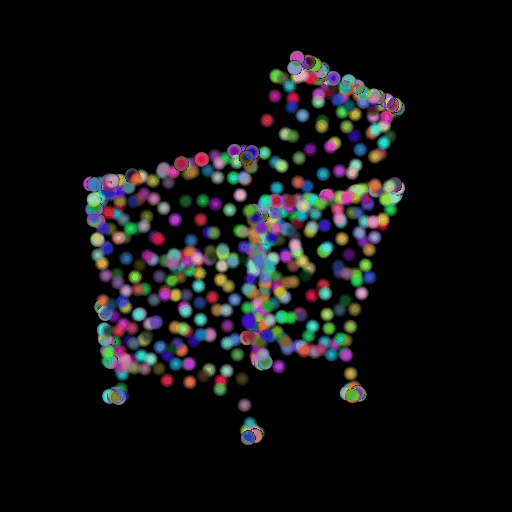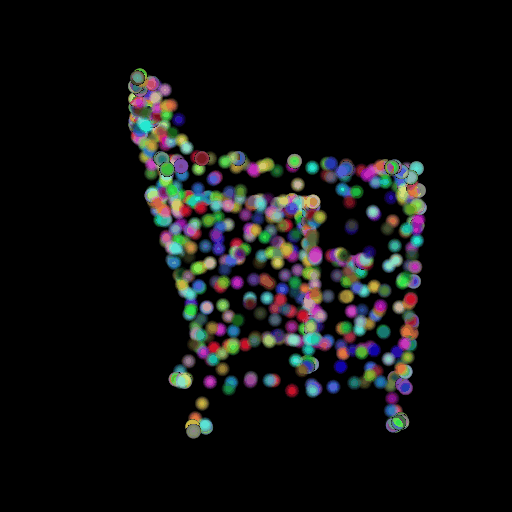

1.3 Fitting a Mesh


2.1 Image to
Voxel Grid
Input RGB Predicted GT









2.2 Image to
Point Cloud
Input RGB Predicted GT

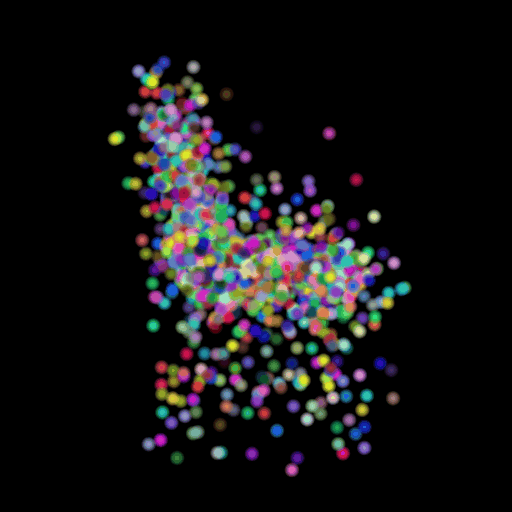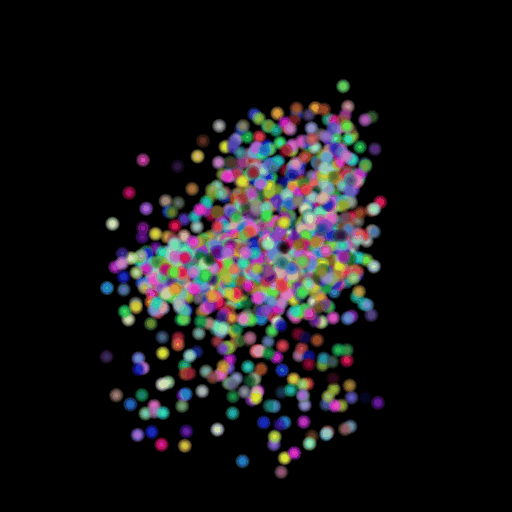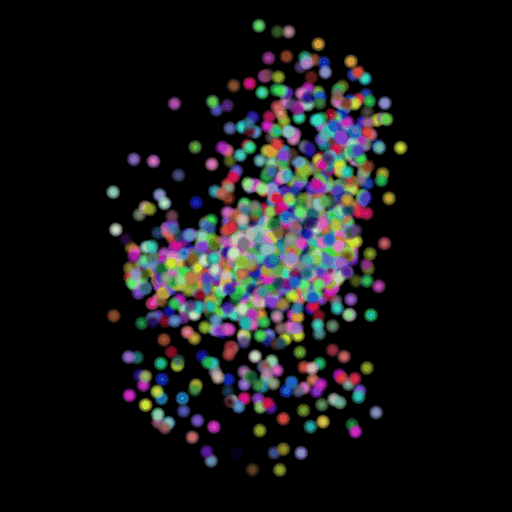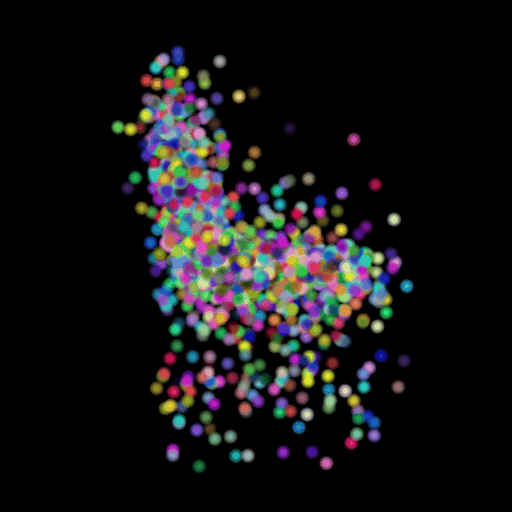
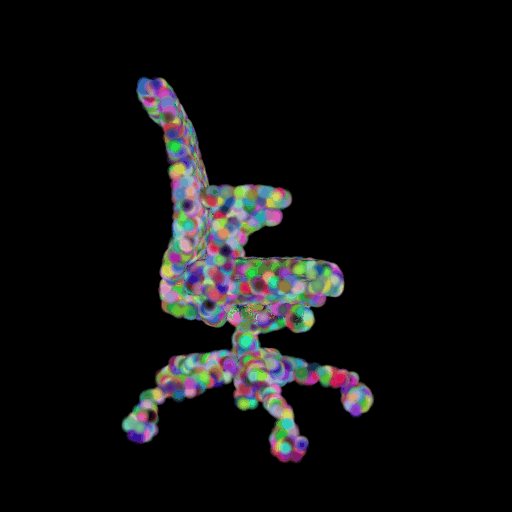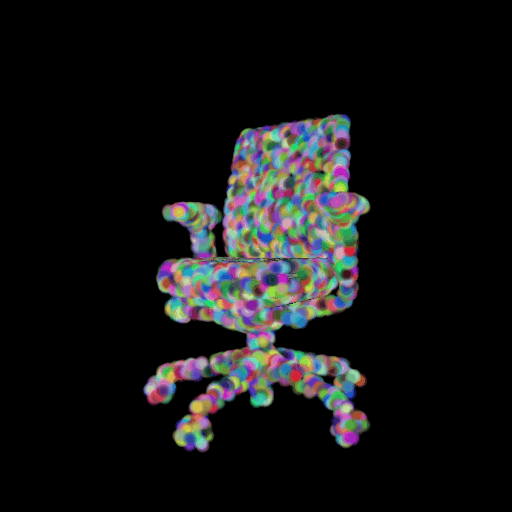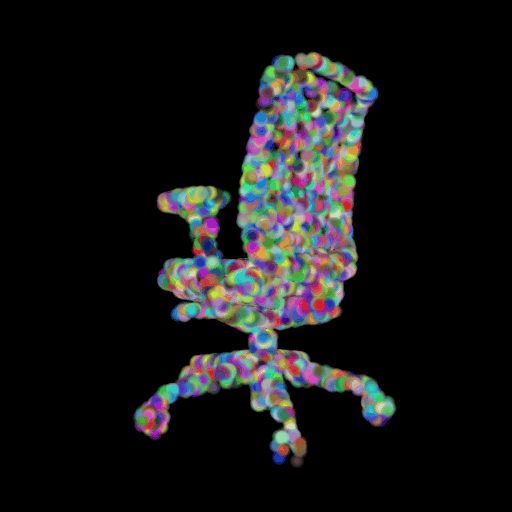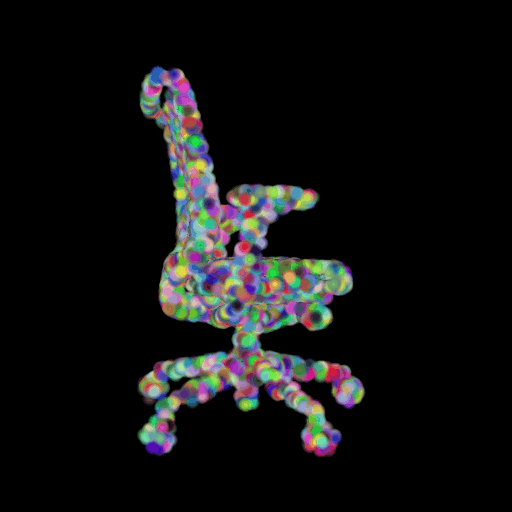

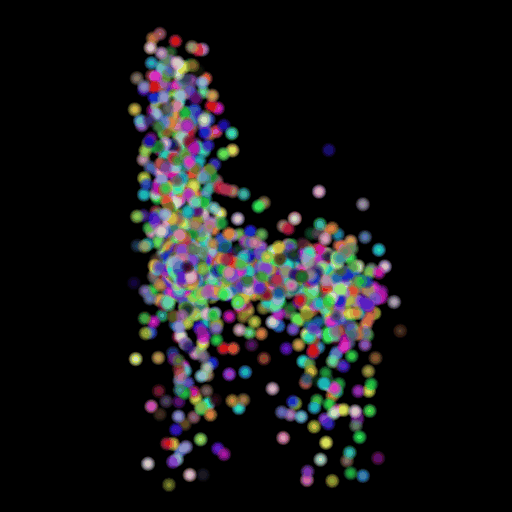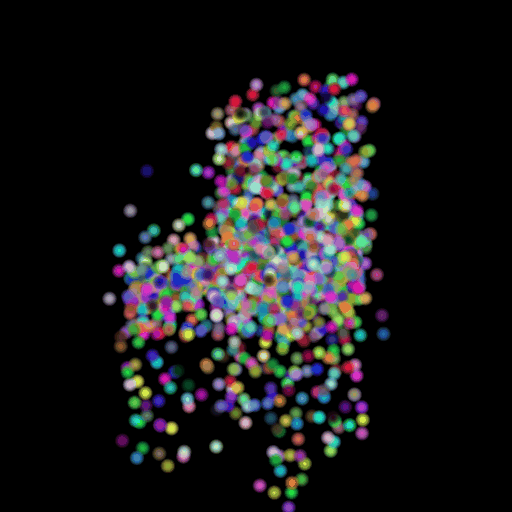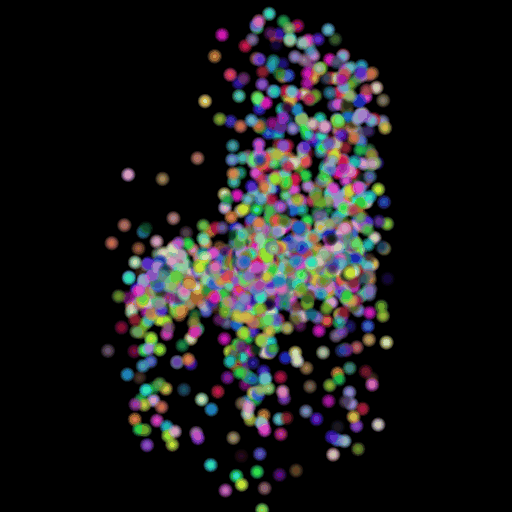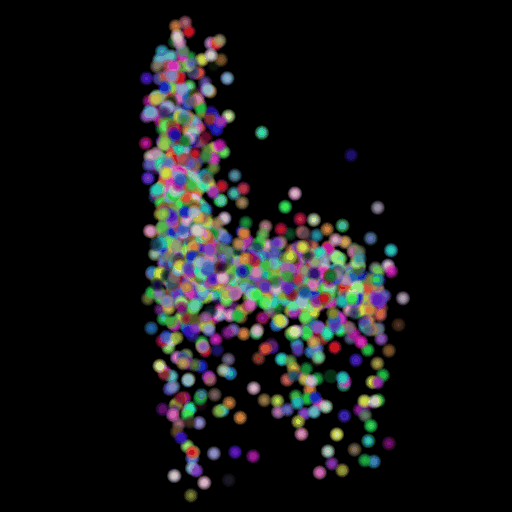
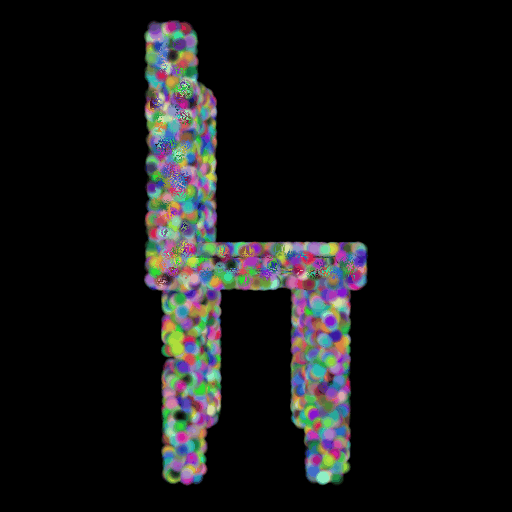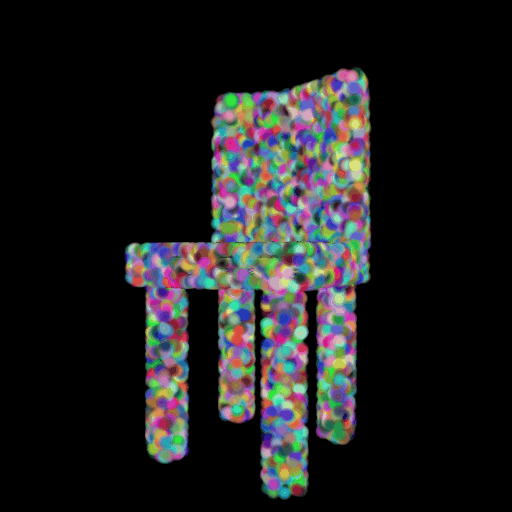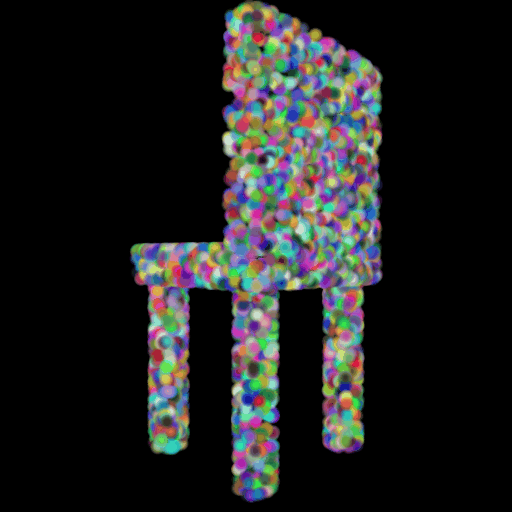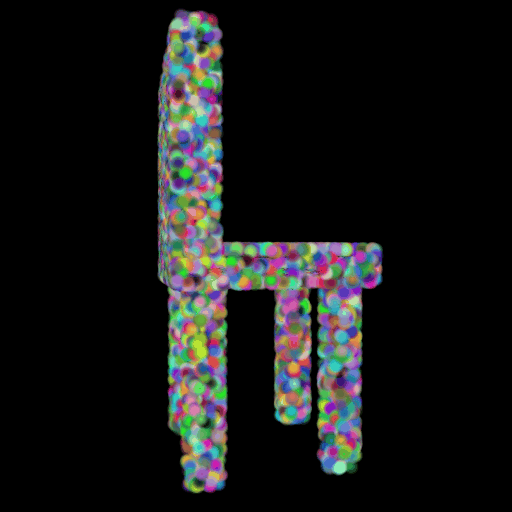


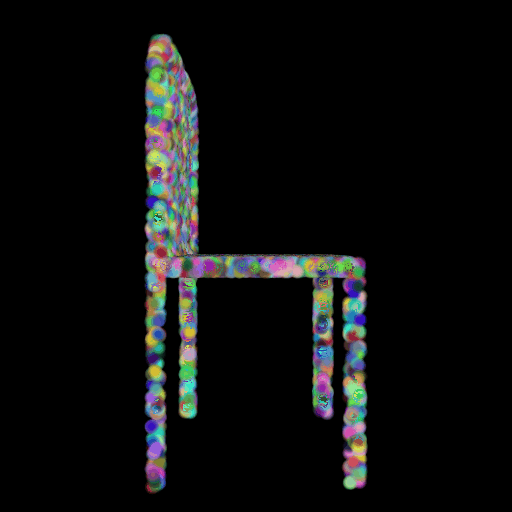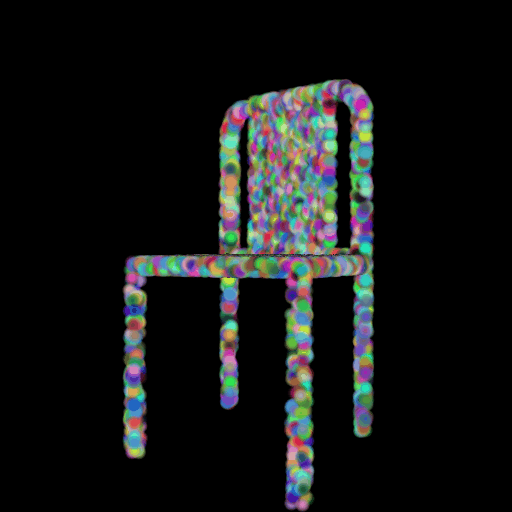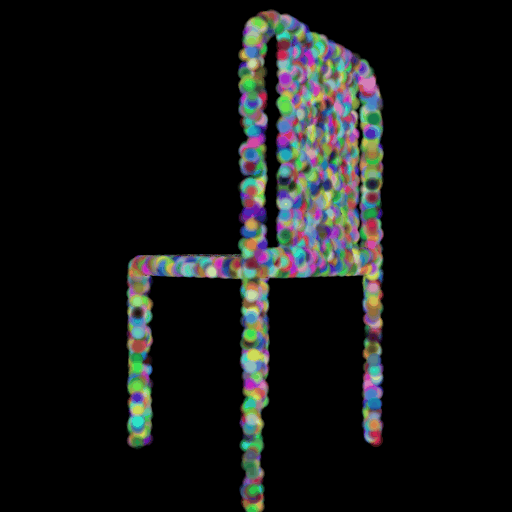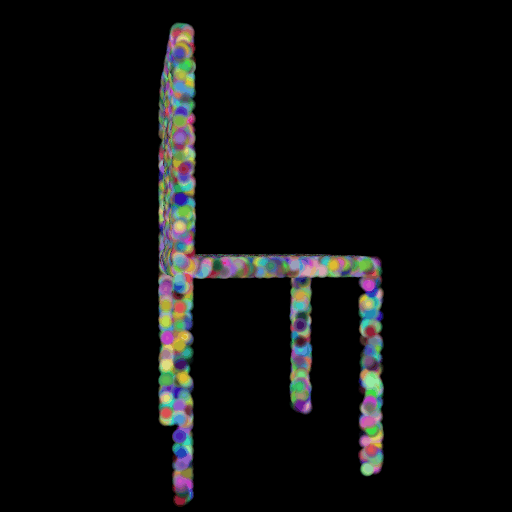
2.3 Image to Mesh
Input RGB Predicted GT








2.4 Quantitative Comparison
|
Voxel (Avg F1@0.05) |
Points (Avg F1@0.05) |
Mesh (Avg F1@0.05) |
|
72.671 |
85.330 |
87.228 |
The results indicate that Mesh representations learn the best transformations followed by Point Cloud. Voxel representations perform the worst. This makes intuitive sense for multiple reasons. Voxels discretize the 3d space into a grid and hence are reliant on the specified resolution. For our use case the resolution is given as 32x32x32 which seems incapable of mapping the finer details of chairs such as holes and intricate design patterns. Meshes and point clouds are better suited to represent these specific patterns and hence are found to perform better.
2.5 Hyperparameter
Variations
Points 500 = Avg F1@0.05: 77.538
Points 5000 = Avg F1@0.05:
85.330
Point 15000 = Avg F1@0.05:
89.202
I used the n_points
hyperparameter and varied its value in the set (500,5000,15000). The results of
this experiment are shown in the table and visualization below. I found that
the model performs the worst when the points are set at the lowest and
gradually improves as the number of points is increased. This makes sense because
as we increase the points, we are also increasing the representative power of
our 3d model. More points can map finer details in chair designs and model a
wide range of patterns found across the test set. This can be seen in the
visualizations below where the lower half of the chair is captured in much more
detail when we use 15,000 points.
GT Image N = 500 points N = 5000 points N = 15000 points

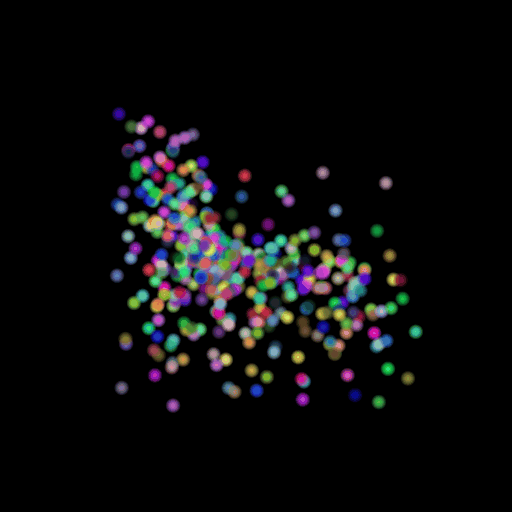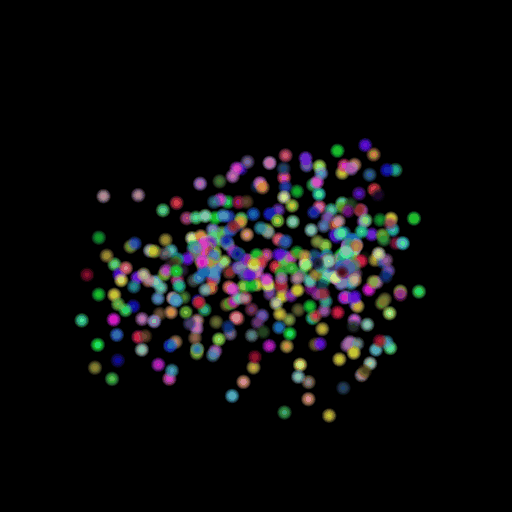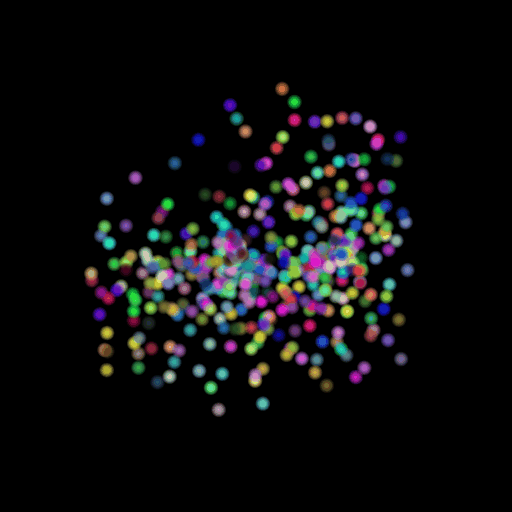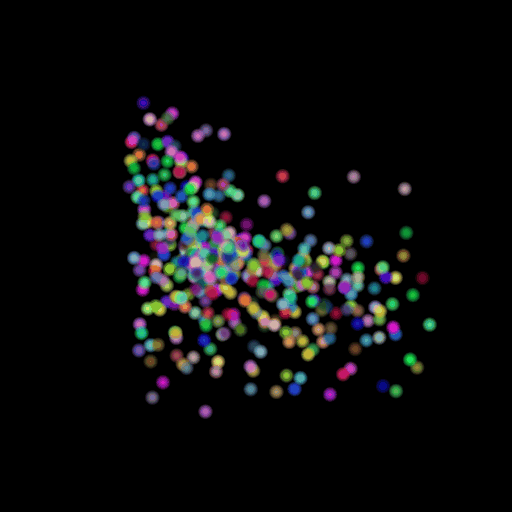
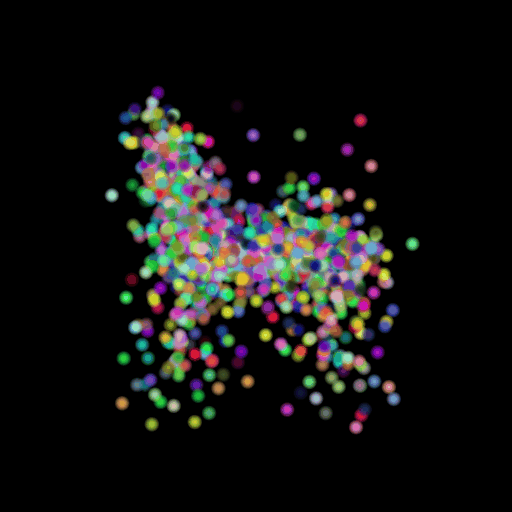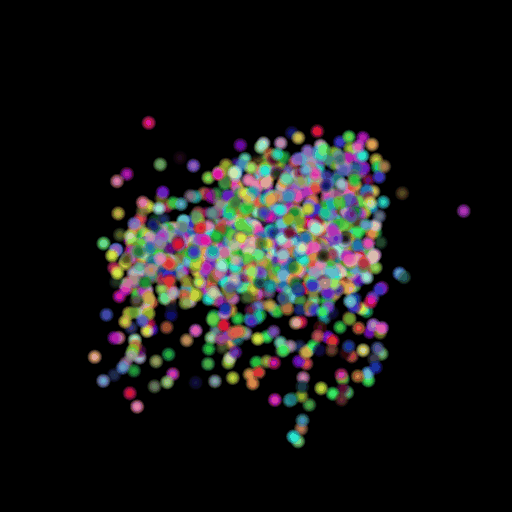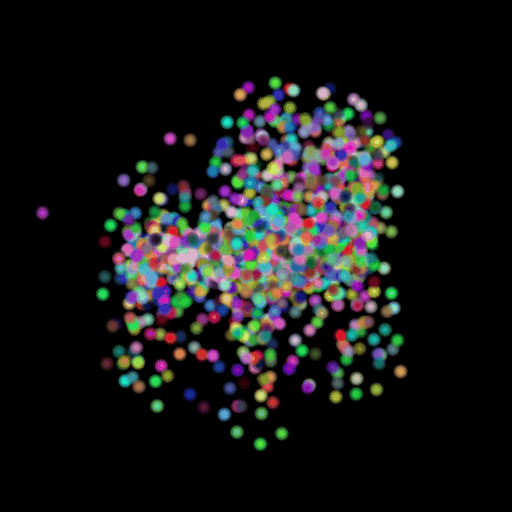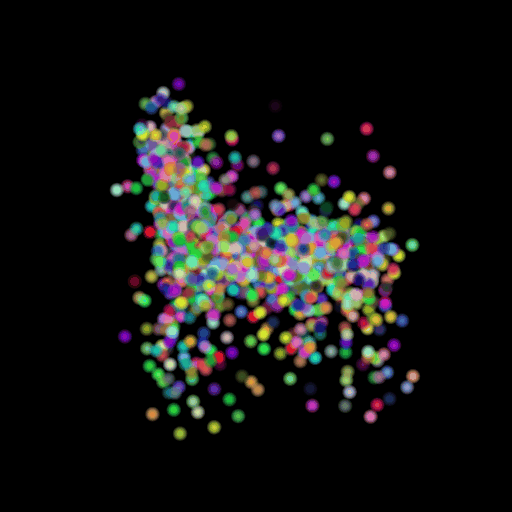
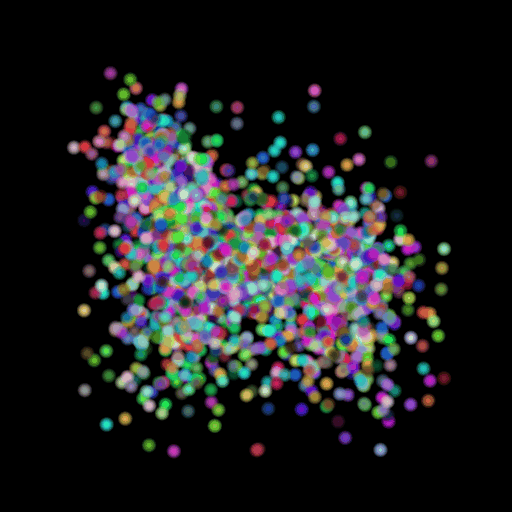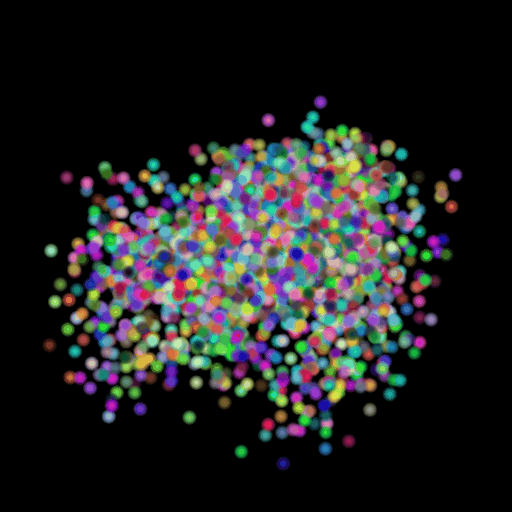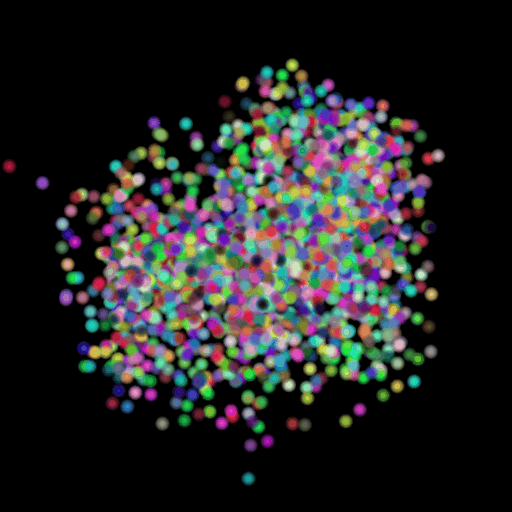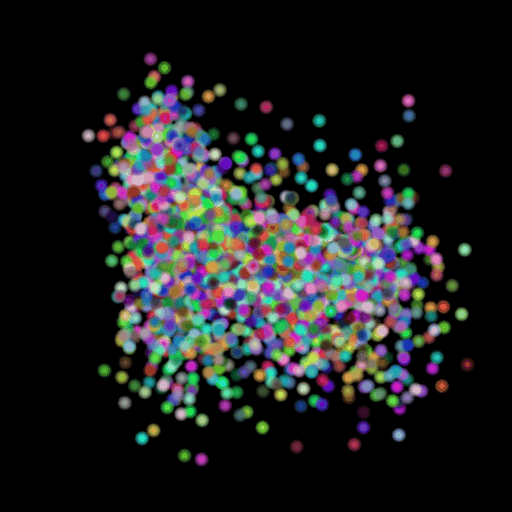
2.6 Interpret
Model – Analyzing Autoencoder latent vector space
In this section, I decided to analyze the intermediate latent vector representation between the encoder and decoder. Several papers have shown that intermediate vectors in auto-encoder style models capture semantic information about the input sample. Based on that, my intention was to check if this vector learns interesting properties about various chairs in the dataset. My hypothesis was that given a query chair’s latent vector, if I found it’s K nearest neighbors in this latent space, I would probably be able to obtain chairs that look similar to the source chair. This is validated in the results below where I show 4 chairs that were found closest to the query chair (arranged in descending order of similarity) in the intermediate latent space. This indicates that our autoencoder model is learning useful semantic information about chairs as it learns to predict their 3d structure.
Query Chair Closest
neighbors in intermediate Autoencoder Latent Space









