16-889: Learning for 3D Vision
Assignment-1
Aditya Ghuge aghuge
Late days used: 0

1. Differentiable Volume Rendering
1.3. Ray sampling
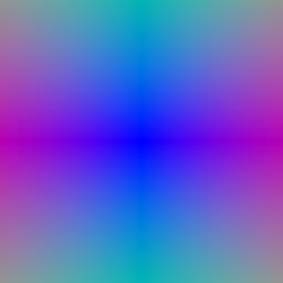
Grid Visualization Ray visualization

1.4. Point sampling
Visualization

1.5. Volume rendering
Visualizations
Gif Depth image

2. Optimizing a basic implicit volume
2.1. Random ray sampling
Done
2.2. Loss and training
Done
2.3. Visualization
Box Center and Side lengths
|
Value |
My Output |
|
Center |
(0.2504141330718994,
0.25044846534729004, -3.26029330608435e-05) |
|
Side Lengths |
(2.0049538612365723,
1.5036567449569702, 1.5035247802734375) |
3. Optimizing a Neural Radiance Field

4. NeRF Extras
4.1 View Dependence

Discuss the trade-offs between increased view dependence and
generalization quality.
Comparing the the gif from above we can see the output presented
by adding view dependance produces better results. Without view dependance we
predict color and density based on 3D points. Thus, it can cause to predict some
artifacts.
On
adding view dependance we get a much more realistic output. The color of output
changes slightly with viewing direction which is a realistic property. This property
can produce better outputs containing reflection. The image looks much sharper.
4.3 High Resolution Imagery
n_pts_per_ray:
100

n_pts_per_ray:
128

n_pts_per_ray:
256

Hidden_layer_dims
256 points per ray 128

Inference:
The output becomes clearer and more realistic as we increase points per ray. It makes back of the bulldozer more realistic as we sample more points along the ray. The bulldozer gif looks more sharper as we increase points. The downside is the computation as it increases significantly as we increase points thus taking longer time to train. Similar trend is observed by increasing neurons in hidden layers as they can better produce the output.