Research Overview
Our vision is to democratize AI by transcending the need for big compute and big data. We design scalable and sample-efficient algorithms that enable users to perform accurate training and inference. We are particularly interested in deploying AI in distributed, heterogeneous settings with communication, computation, and data constraints.
Tools and Approach
We use a diverse set of analytical tools drawn from optimization, applied probability, statistics, queueing theory, and coding theory. Our approach involves the following steps, often traversed in an iterative manner:
- Choosing a model that captures the essential elements of the system, while being simple and tractable.
- Designing algorithms that are provably optimal within the model framework.
- Evaluating the proposed algorithms on the real system, going beyond the assumptions of the model.
Selected Projects and Talk Videos
Communication-Efficient Aggregation Methods for Federated Learning
 Data heterogeneity and communication limitations are two key challenges in federated learning. In this project we design optimization algorithms that improve convergence in the presence of data heterogeneity by only modifying the serve-side aggregation procedure. We also design communication-efficient aggregation methods that can result in a better merged global model than vanilla averaging.
Data heterogeneity and communication limitations are two key challenges in federated learning. In this project we design optimization algorithms that improve convergence in the presence of data heterogeneity by only modifying the serve-side aggregation procedure. We also design communication-efficient aggregation methods that can result in a better merged global model than vanilla averaging.
- FedFisher: Leveraging Fisher Information for One-Shot Federated Learning
- Divyansh Jhunjhunwala, Shiqiang Wang, and Gauri Joshi International Conference on Artificial Intelligence and Statistics (AISTATS), May 2024
- Divyansh Jhunjhunwala, Shiqiang Wang, Gauri Joshi
- International Conference on Learning Representations (ICLR), May 2023
- Selected for a Spotlight presentation (top 25% of accepted papers)
- Divyansh Jhunjhunwala, Ankur Mallick, Advait Gadhikar, Swanand Kadhe, Gauri Joshi
- Neural Information Processing Systems (NeurIPS), Dec 2021
Learning-Augmented Routing Methods for Multi-server Queueing Systems
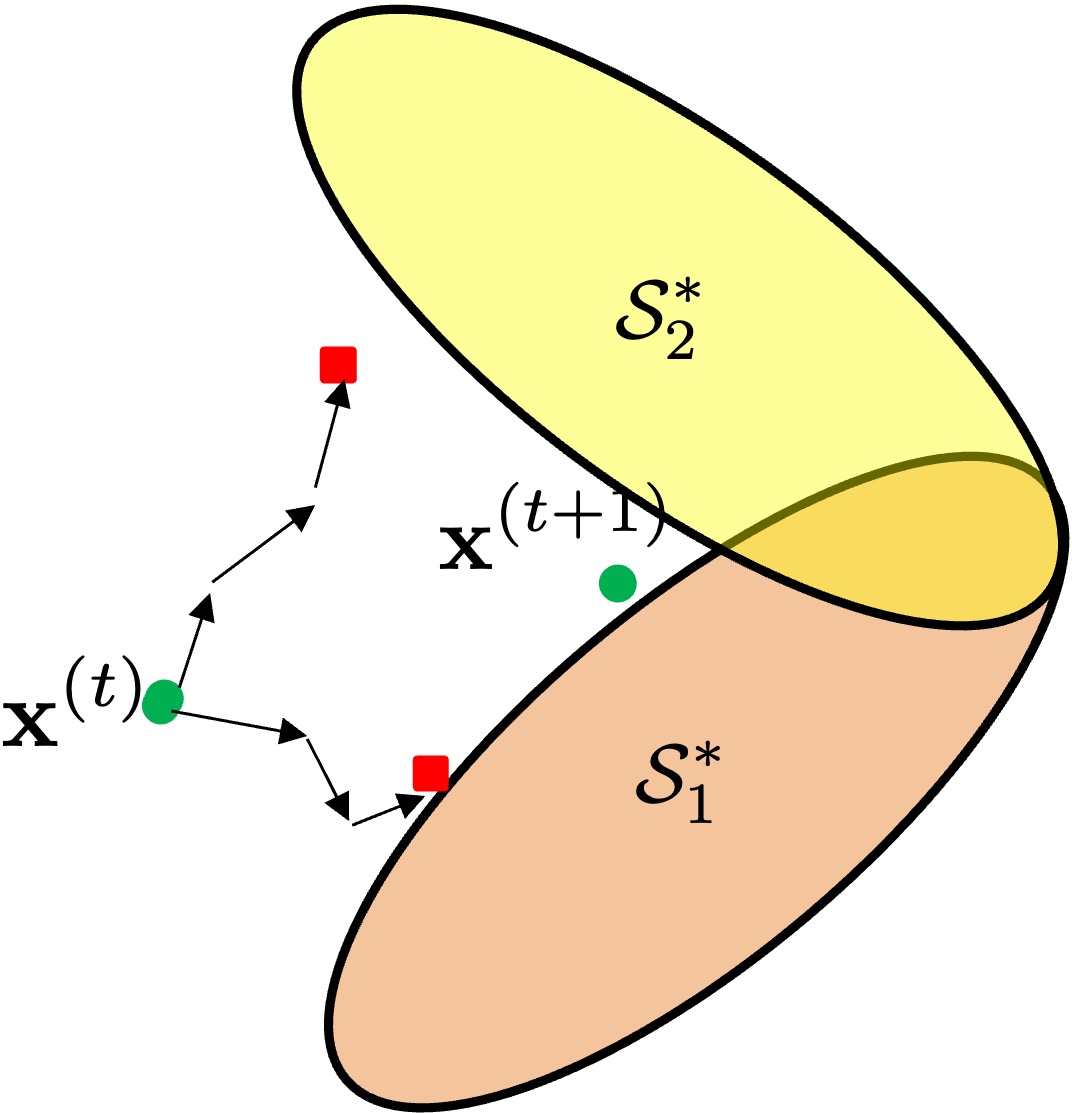
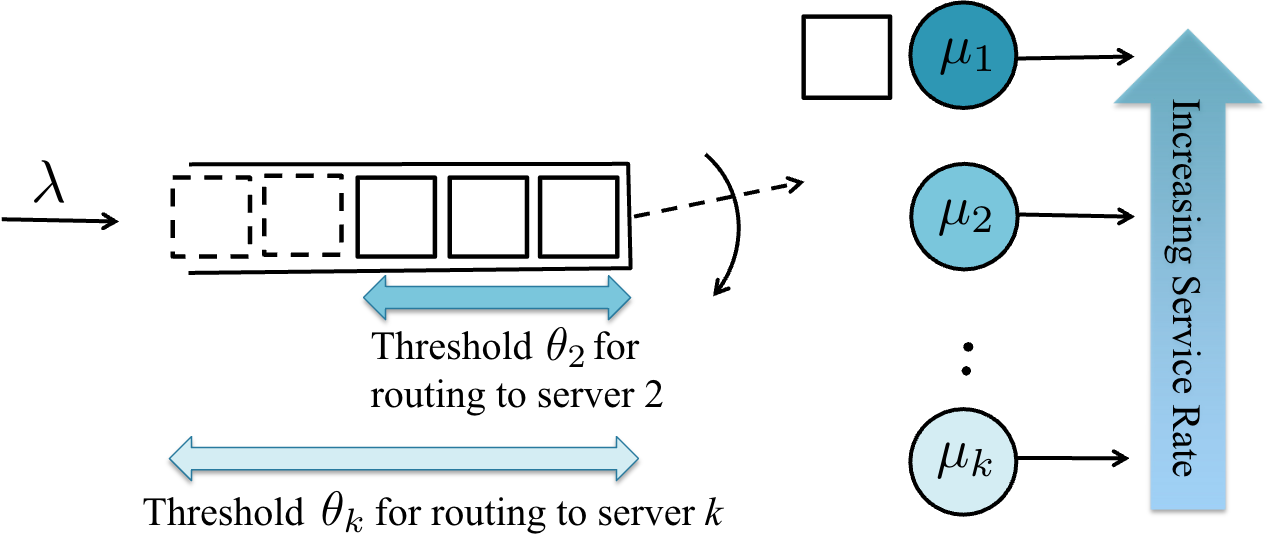 In multi-server queueing systems, classic job dispatching policies such as join-the-shortest-queue and shortest expected delay assume that the service rates and queue lengths of the servers are known to the dispatcher. We address the problem of job dispatching without the knowledge of service rates and queue lengths, where the dispatcher can only obtain noisy estimates of the service rates by observing job departures. In systems where parameters of the optimal policy such as the thresholds for routing to faster versus slower servers are difficult to find, we use reinforcement learning to learn the optimal policy.
In multi-server queueing systems, classic job dispatching policies such as join-the-shortest-queue and shortest expected delay assume that the service rates and queue lengths of the servers are known to the dispatcher. We address the problem of job dispatching without the knowledge of service rates and queue lengths, where the dispatcher can only obtain noisy estimates of the service rates by observing job departures. In systems where parameters of the optimal policy such as the thresholds for routing to faster versus slower servers are difficult to find, we use reinforcement learning to learn the optimal policy.
- Efficient Reinforcement Learning for Routing Jobs in Heterogeneous Queueing Systems
- Neharika Jali, Guannan Qu, Weina Wang, and Gauri Joshi International Conference on Artificial Intelligence and Statistics (AISTATS), May 2024
- Tuhinangshu Choudhury, Gauri Joshi, Weina Wang and Sanjay Shakkottai
- ACM MobiHoc, July 2021
Federated Reinforcement Learning
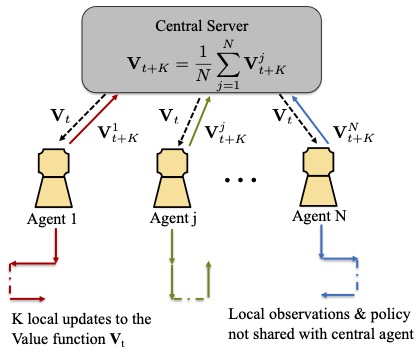 Federated reinforcement learning is a framework where the task of sampling observations from the environment is usually split across multiple agents. The N agents collaboratively learn a global model, without sharing their individual data and behavior policies. This global model is the unique fixed point of the average of N local operators, corresponding to the N agents. Each agent maintains a local copy of the global model and updates it using locally sampled data. In this project, we design federated versions of RL algorithms such as Q-learning and TD-learning and analyze their sample and communication complexity.
Federated reinforcement learning is a framework where the task of sampling observations from the environment is usually split across multiple agents. The N agents collaboratively learn a global model, without sharing their individual data and behavior policies. This global model is the unique fixed point of the average of N local operators, corresponding to the N agents. Each agent maintains a local copy of the global model and updates it using locally sampled data. In this project, we design federated versions of RL algorithms such as Q-learning and TD-learning and analyze their sample and communication complexity.
- The Blessing of Heterogeneity in Federated Q-learning: Linear Speedup and Beyond
- Jiin Woo, Gauri Joshi, and Yuejie Chi
- Journal on Machine Learning Research (JMLR), Feb 2025
- shorter version in International Conference on Machine Learning (ICML), July 2023
- Federated Offline Reinforcement Learning: Collaborative Single-Policy Coverage Suffices
- Jiin Woo, Laixi Shi, Gauri Joshi, and Yuejie Chi
- International Conference on Machine Learning (ICML), July 2024
- Federated Reinforcement Learning: Communication-Efficient Algorithms and Convergence Analysis
- Sajad Khodadadian, Pranay Sharma, Gauri Joshi, Siva Theja Maguluri International Conference on Machine Learning (ICML), July 2022
- selected for a long presentation (2.1% of submitted papers)
Erasure-Coding for Non-Linear Inference Computations
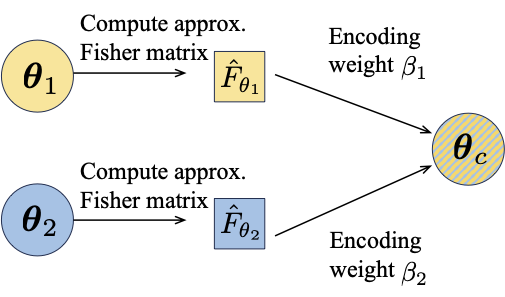 Erasure-coded computing has been successfully used in cloud systems to reduce tail latency caused by factors such as straggling servers and heterogeneous traffic variations. A majority of cloud computing traffic now consists of inference on neural networks on shared resources where the response time of inference queries is also adversely affected by the same factors. However, current erasure coding techniques are largely focused on linear computations such as matrix-vector and matrix-matrix multiplications and hence do not work for the highly non-linear neural network functions. In this paper, we seek to design codes for such non-linear computations. That is, given two or more neural network models, how to construct a coded model whose output is a linear combination of the outputs of the given neural networks.
Erasure-coded computing has been successfully used in cloud systems to reduce tail latency caused by factors such as straggling servers and heterogeneous traffic variations. A majority of cloud computing traffic now consists of inference on neural networks on shared resources where the response time of inference queries is also adversely affected by the same factors. However, current erasure coding techniques are largely focused on linear computations such as matrix-vector and matrix-matrix multiplications and hence do not work for the highly non-linear neural network functions. In this paper, we seek to design codes for such non-linear computations. That is, given two or more neural network models, how to construct a coded model whose output is a linear combination of the outputs of the given neural networks.
- Erasure Coded Neural Network Inference via Fisher Averaging
- Divyansh Jhunjhunwala, Neharika Jali, Gauri Joshi and Shiqiang Wang, International Symposium on Information Theory (ISIT), July 2024
- Ankur Mallick and Gauri Joshi
- Information Theory Workshop (ITW), Nov 2022
- Ankur Mallick, Sophie Smith, Gauri Joshi
- International Symposium on Topics in Coding, Sept 2021
Tackling Computational Heterogeneity in Federated Learning
 The emerging area of federated learning seeks to achieve this goal by orchestrating distributed model training using a large number of resource-constrained mobile devices that collect data from their environment. Due to limited communication capabilities as well as privacy concerns, the data collected by these devices cannot be sent to the cloud for centralized processing. Instead, the nodes perform local training updates and only send the resulting model to the cloud. In this project, we tackle computational heterogeneity in federated optimization, for example, heterogeneous local updates made by the edge clients and intermittent client availability.
The emerging area of federated learning seeks to achieve this goal by orchestrating distributed model training using a large number of resource-constrained mobile devices that collect data from their environment. Due to limited communication capabilities as well as privacy concerns, the data collected by these devices cannot be sent to the cloud for centralized processing. Instead, the nodes perform local training updates and only send the resulting model to the cloud. In this project, we tackle computational heterogeneity in federated optimization, for example, heterogeneous local updates made by the edge clients and intermittent client availability.
- Cooperative SGD: A Unified Framework for the Analysis of Local-Update SGD
- Jianyu Wang, Gauri Joshi
- Journal of Machine Learning Research (JMLR), 2021
- Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization
- Jianyu Wang, Qinghua Liu, Hao Liang, Gauri Joshi, H. Vincent Poor
- Neural Information Processing Systems (NeurIPS), Dec 2020
- Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies
- Yae Jee Cho, Jianyu Wang, Gauri Joshi
- preprint
- Local Adaptivity in Federated Learning: Convergence and Consistency
- Jianyu Wang, Zheng Xu, Zachary Garrett, Zachary Charles, Luyang Liu, Gauri Joshi
- preprint
Asynchronous and Communication-Efficient Distributed SGD
 In large-scale machine learning, training is performed by running stochastic gradient descent (SGD) in
a distributed fashion using multiple worker nodes. Synchronization delays due to straggling workers and communication delays in aggregating updates from worker nodes can significantly increase the run-time of the training job. Our goal is to design a system-aware distributed SGD algorithms that strikes the best trade-off between the
training time, and the error in the trained model.
In large-scale machine learning, training is performed by running stochastic gradient descent (SGD) in
a distributed fashion using multiple worker nodes. Synchronization delays due to straggling workers and communication delays in aggregating updates from worker nodes can significantly increase the run-time of the training job. Our goal is to design a system-aware distributed SGD algorithms that strikes the best trade-off between the
training time, and the error in the trained model.
- Overlap Local-SGD: An Algorithmic Approach to Hide Communication Delays in Distributed SGD
- Jianyu Wang, Hao Liang, Gauri Joshi
- International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2020
- MATCHA: Speeding Up Decentralized SGD via Matching Decomposition Sampling
- Jianyu Wang, Anit Sahu, Gauri Joshi, Soummya Kar
- NeurIPS workshop of Federated Learning for Data Privacy and Confidentiality, Dec 2019
- Distinguished Student Paper Award
- Adaptive Communication Strategies to Achieve the Best Error-Runtime Trade-off in Local-Update SGD
- Jianyu Wang, Gauri Joshi
- SysML Conference, March 2019
- Slow and Stale Gradients Can Win the Race: Error-Runtime Trade-offs in Distributed SGD
- Sanghamitra Dutta, Gauri Joshi, Soumyadip Ghosh, Parijat Dube, Priya Nagpurkar,
- International Conference on Artificial Intelligence and Statistics (AISTATS), Apr 2018
Correlated Multi-armed Bandits

Multi-armed bandit algorithms have numerous data-driven decision-making applications including advertising, A/B testing and hyper-parameter tuning. Unlike classic works that assume independence of the rewards observed by sampling different arms, we consider correlated rewards. This correlation can be exploited to identify sub-optimal or "non-competitive" arms and avoid exploring them. This allows us to reduce a K armed bandit problem to a C armed bandit problem, where C is the number of "competitive" arms.
- Best-arm Identification in Correlated Multi-armed Bandits
- Samarth Gupta, Gauri Joshi, Osman Yagan
- Journal on Selected Areas of Information Theory (JSAIT) Special Issue on Sequential, Active, and Reinforcement Learning, 2021
- Multi-armed Bandits with Correlated Arms
- Samarth Gupta, Shreyas Chaudhari, Gauri Joshi, Osman Yagan
- IEEE Transactions on Information Theory, May 2021
- A Unified Approach to Translate Classic Bandit Algorithms to the Structured Bandit Setting
- Samarth Gupta, Shreyas Chaudhari, Subhojyoti Mukherjee, Gauri Joshi, Osman Yagan
- Journal on Selected Areas of Information Theory (JSAIT) Special Issue on Estimation and Inference, 2021
- Correlated Multi-armed Bandits with a Latent Random Source
- Samarth Gupta, Gauri Joshi, Osman Yagan
- International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2020
Redundancy in Parallel Computing

In large-scale computing where a job is divided into parallel tasks that are run on different computing, slow or straggling nodes can become the bottleneck. We use redundancy in the form of replication or erasure coding to design robust distributed computing algorithms that can seamless adjust to varying node computation speeds. Applications include distributed matrix computations, data analytics and inference.
- Rateless Codes for Near-Perfect Load Balancing in Distributed Matrix-vector Multiplication
- Ankur Mallick, Malhar Chaudhari, Ganesh Palanikumar, Utsav Sheth, Gauri Joshi
- ACM SIGMETRICS, June 2020
- Best Paper Award
- Efficient Redundancy Techniques for Latency Reduction in Cloud Systems
- Gauri Joshi, Emina Soljanin and Gregory Wornell,
- ACM Transactions on Modeling and Performance Evaluation of Computing Systems, 2017