Project Description
The goal of this project is to better understand the Generative Adversarial Networks (GANs) by getting hands-on experience coding and training GANs. We have done experiments with two GAN architectures and one diffusion model:
- DCGAN: short for "Deep Convolutional GAN", is simply a GAN that uses a convolutional neural network as the discriminator, and a network composed of transposed convolutions as the generator. We use DCGAN to generate realistic grumpy cat images from samples of random noise.
- CycleGAN: a more complex GAN architecture that consists of 2 generators and 2 discriminators. CycleGAN was designed to perform image-to-image translation from one domain to another. We use CycleGAN to convert between different types of two kinds of cats (Grumpy and Russian Blue), and between apples and oranges.
- Diffusion Model: a generative model that generate an image starting from a random noise and gradually refining it through a process that mimics diffusion. In this project we used diffusion model to generate cat images similar to our cat dataset.
I. Deep Convolutional GAN
Model Architecture
A DCGAN is simply a GAN that uses a convolutional neural network as the discriminator, and a network composed of transposed convolutions as the generator. nstead of using transposed convolutions, we use a combination of a upsampling layer and a convoluation layer to replace transposed convolutions. Here are the architectures of our discriminator and generator:
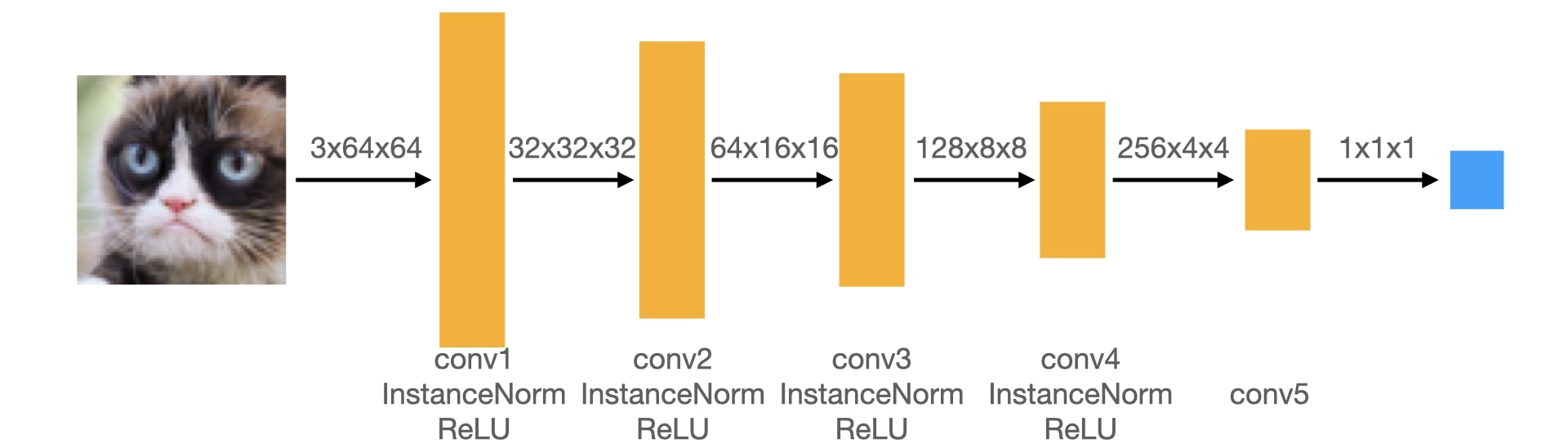
Padding Size
We know that the output size formula is \[n_{out} = \left \lfloor \frac{n_{in}+2p-k}{s}\right \rfloor + 1 \] where $n_{out}$, $n_{in}$ are output/input sizes, $p$ is the padding size, $k$ is the kernel size. In our use case, no floor-rounding is involved. So we remove the floor operation and then get the equation to calculate padding size as following: \[ p = \frac{(n_{out}-1)\cdot s - n_{in} + k}{2}. \] When $n_{in} = 2\cdot n_{out}$, $s=2$, $k=4$, following the equation above we can get $p=1$.
Training Loop
Here is the pseudocode of the training loop that we use to train the DCGAN:

Training Loss Curves
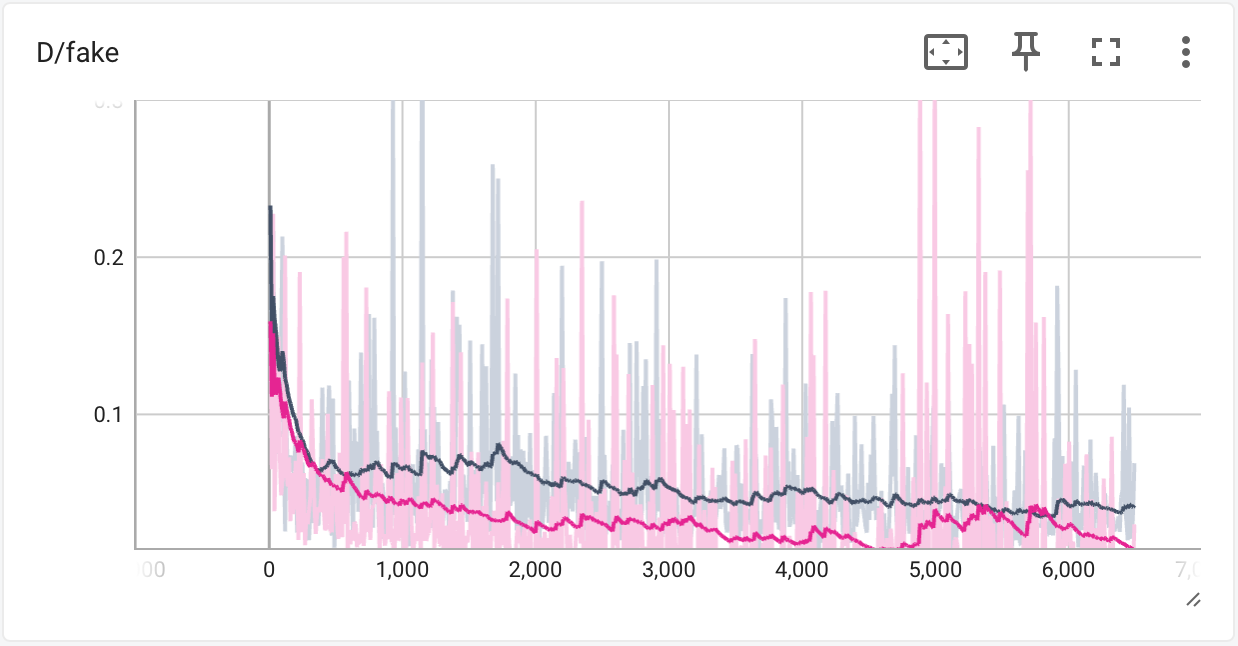
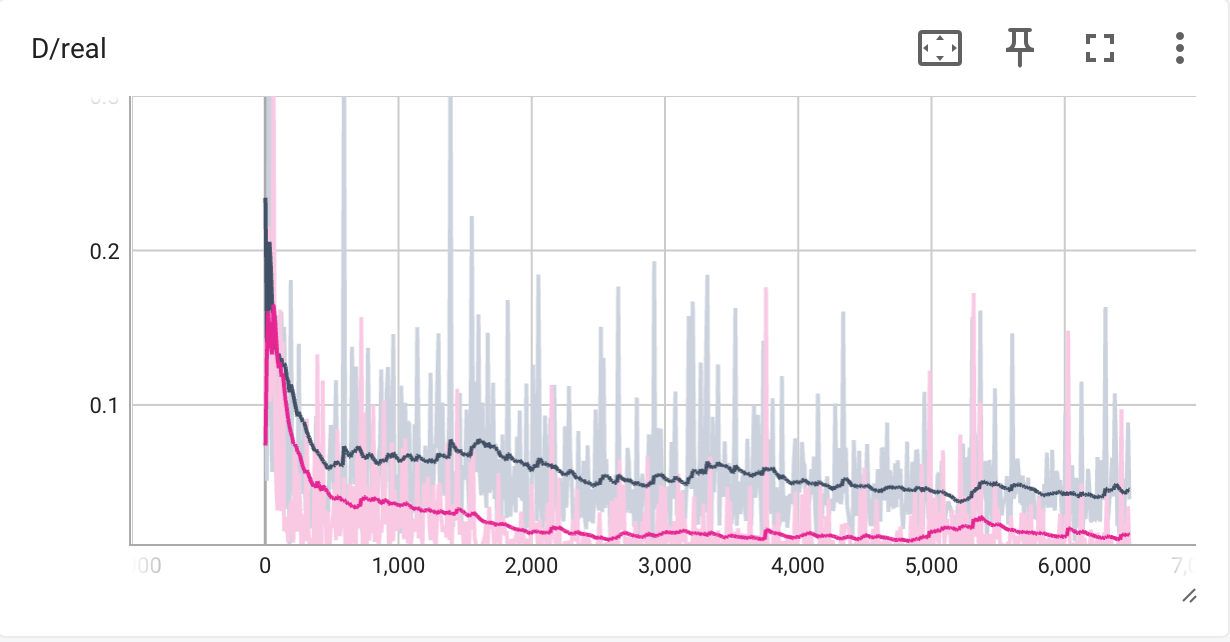
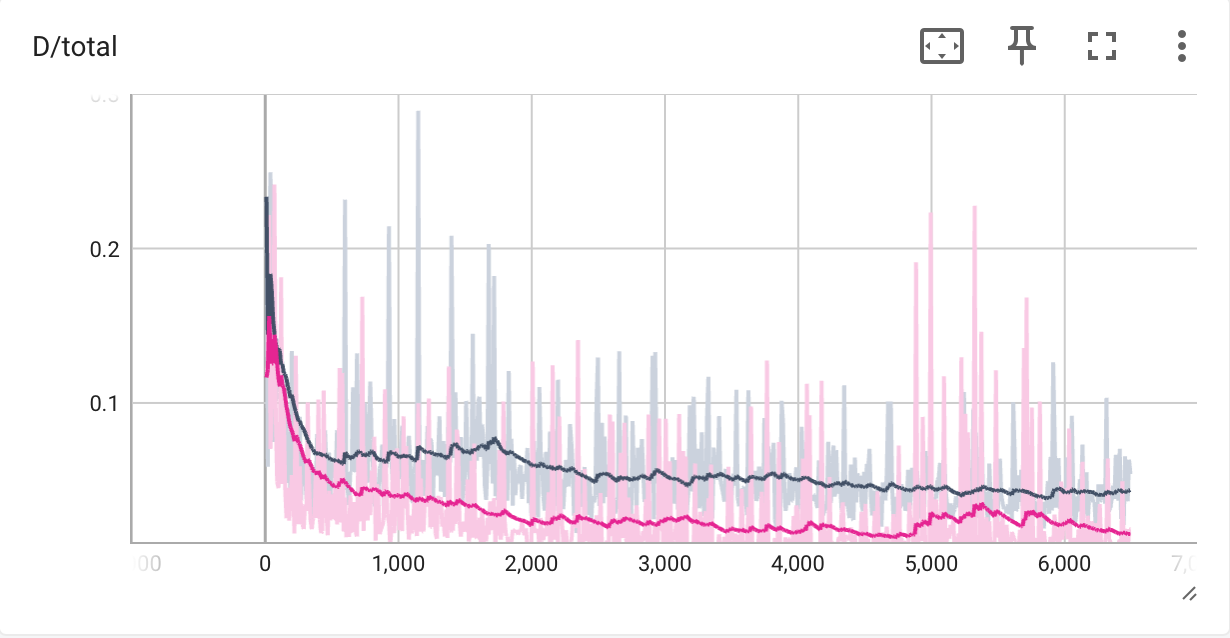
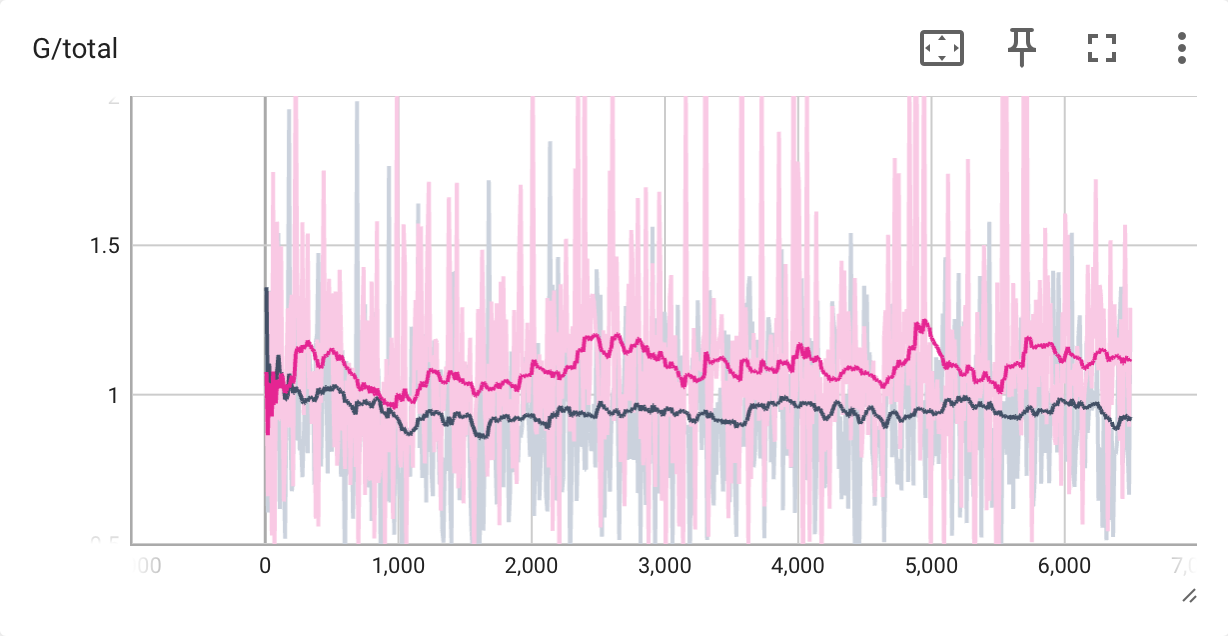


The following samples are produced by DCGAN with trainig flags --data_preprocess=deluxe and --use_diffaug, at iteration 200 and 6400.


We find that the images produced by the DCGAN trained for 6400 iterations are better than that of 200 iterations. Specifically, the structure of the cats' faces becomes more identifiable and clear, the color is more consistent, and there is less noise.
Differentiable Augmentation
We apply differentiable augmentations following this paper to both the real and fake images during training time. Here is the comparison of images without/with differentiable augmentation.

--use_diffaug
--use_diffaugDCGAN trained with differentiable augmentation tends to produce cats with both eyes with more probability than that without differentiable augmentation. Generally speaking, DCGAN with differentiable augmentation tends to produce image with better quality. In terms of the difference in implementation, the traditional data augmentation only preturbs the real images, while the differentiable augmentation preturbs both the real images and the generated images in runtime.
II. CycleGAN
Modle Architecture
CycleGAN consists of two generators, each of them can transfer an image from domain X to domain Y or the other way around. Thus to train a CycleGAN we need two descriminators. One for the domain X, and the other one for domain Y. The two generators are different instances of the same model architecture as shown below:
We adopt a patch-based discriminator architecture for CycleGAN. Instead of directly classifying an image to be real or fake, it classifies the patches of the images, allowing CycleGAN to model local structures better. To achieve this effect, we let the discriminator to produce 4x4 spatial outputs for each image, instead of a 1x1 scalar.
Training Loop
Here is the training loop of CycleGAN:

The most interesting idea behind CycleGANs (and the one from which they get their name) is the idea of introducing a cycle consistency loss to constrain the model. The idea is that when we translate an image from domain $X$ to domain $Y$, and then translate the generated image back to domain $X$, the result should look like the original image that we started with. The cycle consistency loss can be mathematically described as: \[ \mathit{J}_\mathit{Cycle}^{(Y\rightarrow X\rightarrow Y)} = \frac{1}{m} \sum_{i=1}^m ||y^{(i)} - G_{X\rightarrow Y}(G_{Y\rightarrow X}(y^{(i)}))||_p \] where $p$ is traditionally chosen to be 1.
Experiment Results
grumpifyCat dataset after 10000 iters:




apple2orange dataset after 10000 iters:




On apple2orange dataset, results with cycle-consistency loss are better than those without it. Especially for those pictures in which the apple/orange is held by a human hand, cycle-consistency can better preserve the human skin color. However, on the grumpifyCat dataset, training w/ & w/o cycle-consistency loss doesn't produce much difference. That's probably becuase transforming a cat face from one breed to another is more difficult (as it involving larger shape deformation) than transforming between apples and oranges. And the dataset is not large enough.
grumpifyCat dataset with DC Descriminator and Cycle-consistency loss after 10000 iters:


apple2orange dataset with DC Descriminator and Cycle-consistency loss after 10000 iters:


The DC Descriminator performs worse on both grumpifyCat and apple2orange. On grumpifyCat, the generator tends to generate the same cat face given different inputs (the cycle-consistency loss is used). On apple2orange dataset, the color transfer is less realistic, and for complex scenes the generator tends to change the color of the entire image while not preserving much detailed structures in the image. The underperformnace is probably because the DC Descriminator only produce a global score, thus not incentiving the generator to preserve local details and structures as Patch Descriminator does.
III. Diffusion Model
Denoising Diffusion Probabilistic Models (DDPM)
We implemented and trained the diffusion model on the grumpifyCat dataset, following the Denoising Diffusion Probabilistic Models (DDPM) paper and this tutorial. As for the model architecture, as adopted the UNet architecture with ResNet block and Attention block. Here are the results:






















Pretrained Stable Diffusion Model
We used Stable Diffusion 2.1 to generate several cat images with texts. Here are the results:

