Introduction
With the development and popularization of VR/AR devices, 3D spatial creation and manipulation are becoming increasingly popular among artists. In this project, we aim to create a 3D assets manipulation pipeline that can let users to manipulate the 3D assets using 3D control points as signal. The idea is inspired by DragGAN [10], which uses 2D control points to manipulate 2D images. In our project, we expand this point-based manipulation paradigm into 3D space. Specifically, users can input 3D control point pairs to the 3D model as the dragging signal using a VR/AR headset and controller, and the system will output the edited 3D assets according to the dragging signal. We use 3D Gaussian Splatting (3DGS) [6] as the representation to implement our 3D manipulation pipeline on, as 3DGS has many good properties: (1) it is fast to train and super fast to render, (2) its explicit Gaussian representation makes it easy to manipulate.
While it is possible to directly manipulate the trained Gaussian in 3D to achieve some extent of editing, by integrating it with a generative model like DragGAN enables inpainting disocclusioned areas during manipulation and large geometry changes to the Gaussian with relatively less effort, which is hard to achieve by directly editing the underlying Gaussians. In this project, We provide a DragDiffusion- based 3DGS editing pipeline, editing results, and potentially a user interface for editing as the project outcome.
Related Works
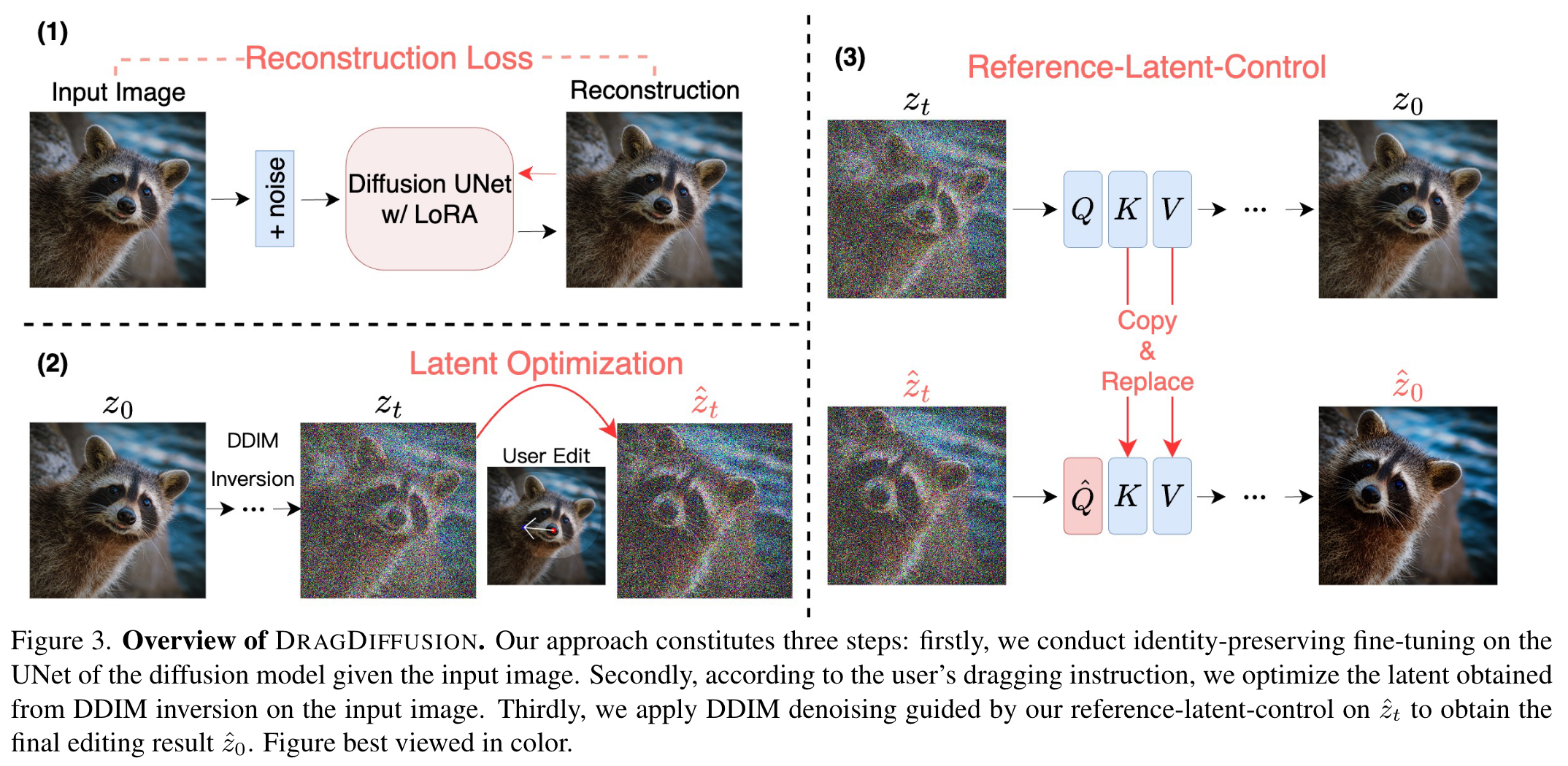
DragGAN [10] is an image manipulation approach that enables interactive and precise point-based manipulation of images generated by Generative Adversarial Networks (GANs). The key idea is to allow users to ”drag” any point in the image to a desired target location, enabling control over the pose, shape, expression, and layout of diverse object categories. DragDiffusion [12] addresses the similar 2D dragging task as the DragGAN does, but it harnesses the power of pretrained Stable Diffusion model to perform the editing.
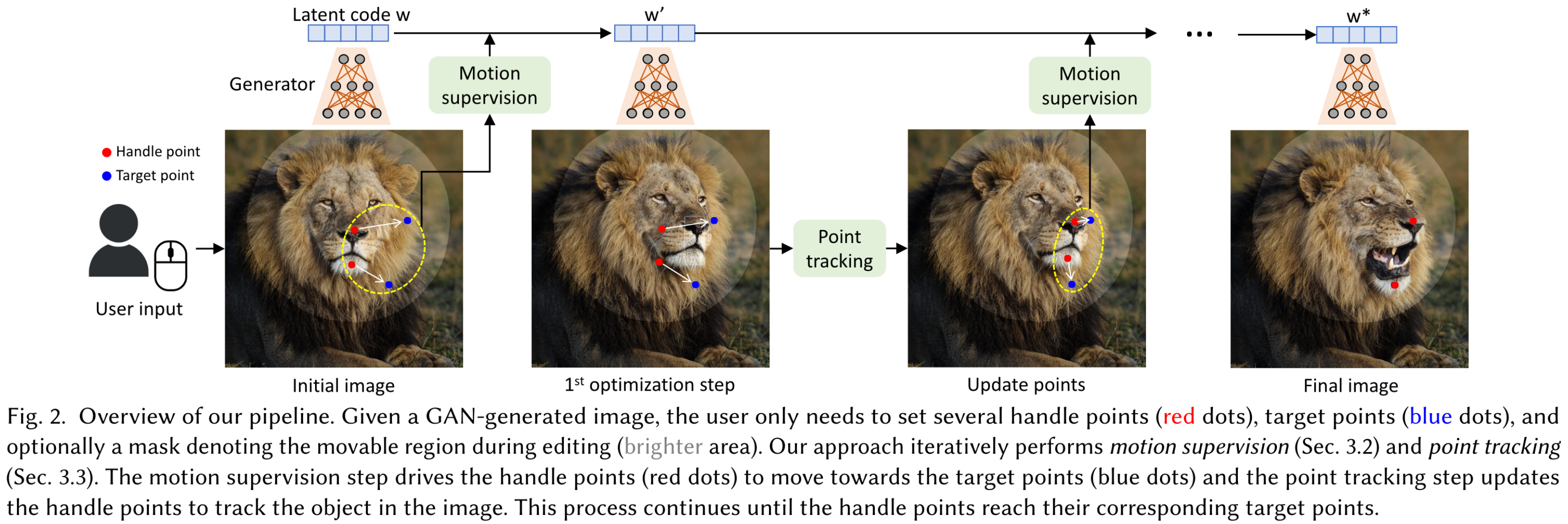
There are some existing works for Gaussian editing [2, 4, 13], leveraging language model to edit the Gaussians following text instructions. While the advances of language models offer a wide range of editorial freedom, text instructions don’t achieve the same intuitive and precise control over what is being edited as the control point does, especially in the context of geometry editing. To the best of our knowledge, so far there’s been no representative work on 3D point-based manipulation with 3DGS.
Another line of works on NeRF editing also exist where the editing is done either through explicit manipulation such as scribbling and mesh deformation [8, 16, 3, 17], or with text prompts and image conditioning [7, 1, 14, 15, 5, 11, 18]. The former line of research allows for precise manipulation on geometry and textures but is constrained to the existing content, and the mesh deformation can be less intuitive for beginner users. The latter direction has limited geometry editing capability and control due to the vagueness of natural language and constraints from the language model used.
Methods
Here is the mathematical description to our problem: Given a 3D object represented by a set of well- optimized 3D Gaussians $G$, and a set of 3D control point pairs ${(p_\text{i, start}, p_\text{i, end})}$, each control point pair is a motion instruction consisting of a starting point and an end point, as input, our method should output the edited 3D Gaussians $G^′$ according to the motion instructions.
Overall, our approach to the problem is similar to the method used in Instruct-NeRF2NeRF [5], where we optimize the Gaussians based on DragDiffusion-edited multi-view rendering from the original Gaussians. The major modifications of our approach lie in the way of processing user input, the optimization scheme, and the solution to potentially inconsistent multi-view edited results.
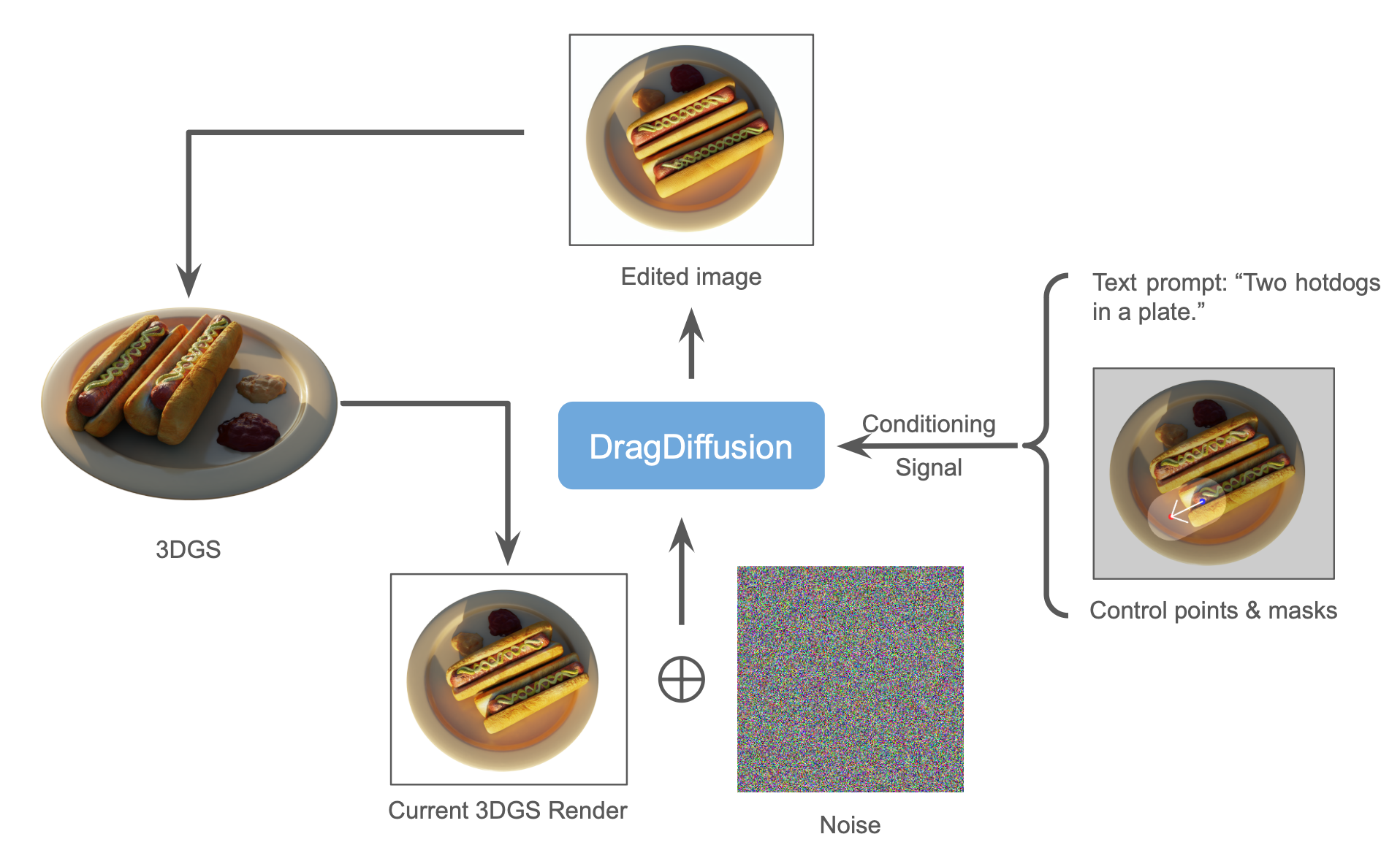
We assume that a set of well-optimized Gaussians of an object is provided. First, randomly sample multiple camera views around the object, render 2D RGB images from these camera views, and project the 3D control points onto these 2D images. Then, apply DragDiffusion [12] to iteratively update each image. Since the 2D manipulation is performed on each image independently and there is no mechanism to explicitly enforce the multi-view consistency during editing, we plan to progressively update the images in a iterative manner. And we optimize the Gaussians after each update to the images. The method will terminate when every projected 2D starting point moves to its corresponding ending point.
Experiments
We iterate between the Gaussian fine-tuning and the image updating in each global iteration. In each iteration, k views are sampled to fine-tune Gaussians and d views are sampled to perform the editing. We record the locations of the handles and the resulting feature map at the end of each editing step. As new images rendered from the Gaussians will be used for editing in the next iteration, we perform an additional point tracking step to find the position of the new handles using the previously stored handles and feature maps. We typically use k = 10 and d = 2000, and run for 15 global iterations.
In our experiments, we notice that Guassians are very sensitive to the slight multi-view inconsistency from the DragDiffusion output. To ensure the unmasked regions of DragDiffusion output match as close to the original images as possible, we optimize LoRA weights for each individual image separately following the DragDiffusion paper, instead of training one LoRA weight using all images. For the reference attention control setting mentioned in the paper, where the authors switch to use cross- attention between the edited images and the original images instead of self-attention, we choose to use the unedited images as reference, rather than using the edited images from the last step.
Even with identity preserving tricks, DragDiffusion may still generate images slightly different from the original images in the unmasked regions. We then take inspirations from Gaussian Editor, where new Gaussians introduced in each densification process are regarded as belonging to the same generation. Right after each densification step, we record all Gaussians’ attributes (positions, colors, rotations, scales, opacities) as the anchor, and apply mean squared error (MSE) between the current and anchor Gaussians’ attributes. The MSE is further weighted by a generation-dependent factor, where older generations are assigned higher anchor loss weights, making them more stable and robust to inconsistent input images. Currently we linearly scale the anchor loss weights based on the generations.
We perform experiments on the NeRF-Synthetic [9] dataset. We compare our iterative dataset update approach to the one-shot dataset update baseline. Here are the qualitative results:






From the results above we can observe that our method can perform more correct update to the image. Our method is more robust to single view image update failure. The results below show an failed update to a view, which leads to conspicuous artifacts to the baseline method (white regions on the chair back), but our method is robust to it.



Failure cases
However, our method is not perfect. The Gaussians suffer from noisy and inconsistent images during fine-tuning and produces low quality reconstruction results. Here we show some failure cases on the novel views below. We will continue improving the results in the future.




References
[1] C. Bao, Y. Zhang, B. Yang, T. Fan, Z. Yang, H. Bao, G. Zhang, and Z. Cui. Sine: Semantic-driven image-based nerf editing with prior-guided editing field. In The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2023.
[2] Y. Chen, Z. Chen, C. Zhang, F. Wang, X. Yang, Y. Wang, Z. Cai, L. Yang, H. Liu, and G. Lin. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting. arXiv preprint arXiv:2311.14521, 2023.
[3] Chong Bao and Bangbang Yang, Z. Junyi, B. Hujun, Z. Yinda, C. Zhaopeng, and Z. Guofeng. Neumesh: Learning disentangled neural mesh-based implicit field for geometry and texture editing. In European Conference on Computer Vision (ECCV), 2022.
[4] J. Fang, J. Wang, X. Zhang, L. Xie, and Q. Tian. Gaussianeditor: Editing 3d gaussians delicately with text instructions. arXiv preprint arXiv:2311.16037, 2023.
[5] A. Haque, M. Tancik, A. Efros, A. Holynski, and A. Kanazawa. Instruct-nerf2nerf: Editing 3d scenes with instructions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023.
[6] B. Kerbl, G. Kopanas, T. Leimku ̈hler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 42(4), July 2023.
[7] S. Kobayashi, E. Matsumoto, and V. Sitzmann. Decomposing nerf for editing via feature field distillation. In Advances in Neural Information Processing Systems, volume 35, 2022.
[8] S. Liu, X. Zhang, Z. Zhang, R. Zhang, J.-Y. Zhu, and B. Russell. Editing conditional radiance fields. In Proceedings of the International Conference on Computer Vision (ICCV), 2021.
[9] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
[10] X. Pan, A. Tewari, T. Leimku ̈hler, L. Liu, A. Meka, and C. Theobalt. Drag your gan: Inter- active point-based manipulation on the generative image manifold. In ACM SIGGRAPH 2023 Conference Proceedings, 2023.
[11] J. Park, G. Kwon, and J. C. Ye. Ed-nerf: Efficient text-guided editing of 3d scene using latent space nerf. arXiv preprint arXiv:2310.02712, 2023.
[12] Y. Shi, C. Xue, J. Pan, W. Zhang, V. Y. Tan, and S. Bai. Dragdiffusion: Harnessing diffusion models for interactive point-based image editing. arXiv preprint arXiv:2306.14435, 2023.
[13] C. Vachha and A. Haque. Instruct-gs2gs: Editing 3d gaussian splats with instructions, 2024.
[14] C. Wang, M. Chai, M. He, D. Chen, and J. Liao. Clip-nerf: Text-and-image driven manipulation
of neural radiance fields. arXiv preprint arXiv:2112.05139, 2021.
[15] C. Wang, R. Jiang, M. Chai, M. He, D. Chen, and J. Liao. Nerf-art: Text-driven neural radiance
fields stylization. arXiv preprint arXiv:2212.08070, 2022.
[16] T. Xu and T. Harada. Deforming radiance fields with cages. In ECCV, 2022.
[17] Y.-J. Yuan, Y.-T. Sun, Y.-K. Lai, Y. Ma, R. Jia, and L. Gao. Nerf-editing: geometry editing of neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18353–18364, 2022.
[18] J. Zhuang, C. Wang, L. Liu, L. Lin, and G. Li. Dreameditor: Text-driven 3d scene editing with neural fields. arXiv preprint arXiv:2306.13455, 2023.