Project 3 - We Need more Cats a.k.a. Training GANs

Generated Grumpy Cats

Russian Blue To Grumpy
Cats are the best pets. They are loving, caring, and attention seeking. The problem is that there are not enough cat pictures in the world, therefore, we need a computer vision model that can generate more cat pictures; enter GANs (Goodfellow et al.), models that train image generators with and adversarial setup together with discriminators. The idea is for the discriminator to distinguish between real and fake cat images while the generator tries to fool the discriminator by learning to generate more real cat images. This setup works really well in practice. In this assignment, we first train a grumpy cat GAN. Then, we train mini CycleGAN that translates grumpy cats into russian blues and vice versa via cycle consistency loss. Finally, we augment our generator in CycleGAN with a mini UNet to compare results.
Grumpy Cat GAN
Here, we train a grumpy cat GAN with a generator and discriminator architecture similar to DCGAN. Below are discriminator and generator loss graphs for our GANs. Note that without differentiable augmentation, the discriminator loss converges really fast to 0 and generator loss shoots up. This is undesirable because the discriminator is too good and the generator stop learning signals to help it generate realistic images. Ideally, discriminator loss should hover around 0.5, meaning the discriminator cannot tell if an image is generated or real. Likewise, the generator loss should also hover above 0.5. We see that with differential augmentation, the discriminator overfits to the real images more slowly and lets the generator learn some useful signals to produce good looking images. Visual results are below.
In basic augmentation, we simply perform resizing and normalization. In deluxe augmentation, we perform a random crop into an image, which lets us get slightly different images each time.
We also perform random horizontal flip and brightness and constrast jittering. We do not perform vertical flip or color jitter because those augmentation results in unrealistic looking cats.
Both basic and deluxe augmentation are performed on the real training images. However, naive augmentation can only help with training the discriminator and not the generator.
In constrast, we have differentiable augmentation which
applies a set of differentiable augmentations such as brightness and constrast jitter, translation, and cutout using differentiable torch functions. We apply differential augmentation before the images are
fed into the discriminator to get the discriminator and generator losses. Note we apply diff aug to both real training images and generated samples. Diff aug helps to reduce overfitting of
discriminator, improve generator, and stabilize GAN training. In practice, diff aug allows GANs to produce significantly more realistic cats even without dexlute augmentation.
Padding. The class implementation of Discrimiantor, we use kernel of 4 and stride of 2 to downsample image by a factor of 2. We use the equation out_dim = (in_dim + 2*pad -k)/stride + 1 where
k is kernel size. Using this equation, we quickly figure out that 8 = (16 + 2*1 - 4)/2 + 1 we need a padding of 1 to downsample effectively. Note that for generator I use kernel of 5,
padding of 2, and stride of 1 to make sure resolution stays the same during convolution and the upsampling is done before convolution. Note we use different padding and kernel for first layer
of generator and last layer of discriminator.
Figure. Losses of GAN with basic/deluxe and optional differentiable augmentation. Top row (discriminator loss (top) and generator loss (below)).
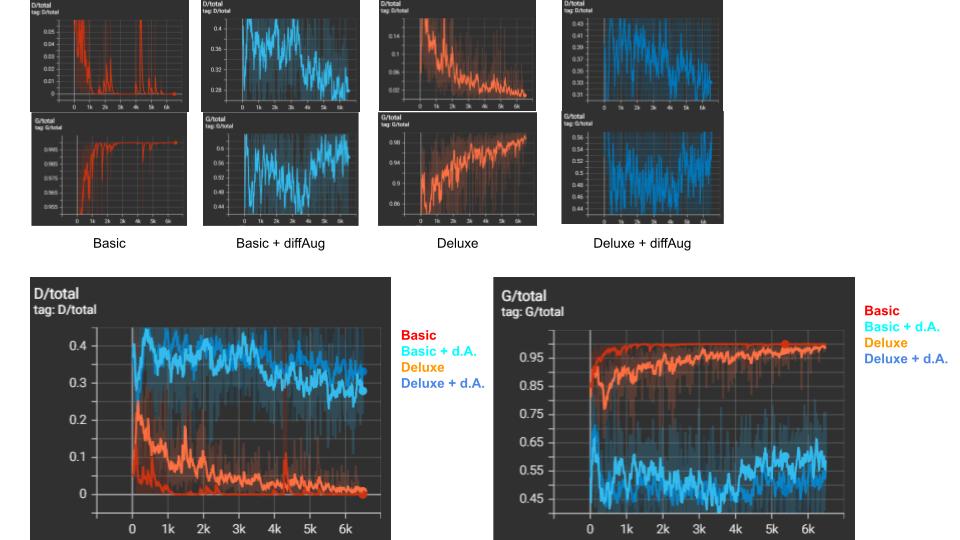
GAN Losses
Figure. Visualization of GANs. We see that diff aug improves results for both basic and deluxe training image augmentation. We see that basic fails. We see that deluxe also produces reasonable results. We see that deluxe + diff aug removes some artifacts from deluxe only. At iteration 200 of deluxe + diffaug we see that generator learned to generate black eye patches and white mouth area. At iteration 5600, we see very realistic grumpy cats.

Basic (5400)

Basic + diff Aug (5400)

Deluxe (5400)

Deluxe + diff Aug (5400)

Deluxe + diff Aug (iteration 200)

Deluxe + diff Aug (iteration 5600)
CycleGAN
In CycleGAN, we want to convert images from domain X to domain Y. For example, grumpy cats into russian blues. However, without paired training images, which are infeasible to get, we cannot train it naively. Thus we introduce CycleGAN. We have two generators (XtoY and YtoX) and discriminators (X and Y). We use XtoY to convert real X to fake Y. Additionally, we enforce a cycle consistency loss which states that real X should be similar to YtoX(XtoY(realX)). We optimize for the L1 between realX and YtoX(XtoY(realX)) in addition to GAN loss on XtoY and YtoX. This helps us ground our two generators such that the generator XtoY or YtoX cannot ignore input and just generate a single target domain image.
Figure. Visualizations for CycleGAN on cats. Note all CycleGAN training uses diffAug and deluxe aug. We see that for all models, results improve from left to right as iteration is increased from 1k to 10k. We notice that for all models, XtoY looks visually better than YtoX. We see the improvement of cycle consistency loss at the location of target domain cat head, eyes, neck, and background. We see that without cycle consistency loss, cats facing a certain direction in input will generate a center facing target domain cat. However, with cycle consistency loss, the generated cats are facing in similar direction with their eyes at similar locations and the background at similar locations. We see that cycle consistency loss improves agreement between target and input drastically.

patch XtoY (iteration 1000)

patch XtoY (iteration 10000)

patch YtoX (iteration 1000)

patch YtoX (iteration 10000)

patch + cycle XtoY (iteration 1000)

patch + cycle XtoY (iteration 10000)

patch + cycle YtoX (iteration 1000)

patch + cycle YtoX (iteration 10000)
Figure. Cycle Consistency Loss Cats. Visualizations of CycleGAN focused around cycle consistency loss. For cats, we see that cycle consistency loss helps to generate cats that look in the same direction, and have similar head and eye positions as input image. Without cycle consistency loss, we see that the generated image is a forward facing cat that does not taken in account of small differences of view direction as input. We see that for cats cycle consistency helps a lot.
patch XtoY cats
patch + cycle XtoY cats
patch YtoX cats
patch + cycle YtoX cats
Figure. Cycle Consistency Loss Apples and Oranges. Visualizations of CycleGAN focused around cycle consistency loss. For apples and oranges, we see that both models without and with cycle consistency loss captures the changes in color well. However, we notice that examples with cycle consistency loss has orange pulp texture artifacts that are not as obvious in an example without cycle consistency loss. We see that with cycle consistency loss, a cut open orange will generate a cut open red orange. Without cycle consistency loss, we see less pulp texture artifacts and more apple textures. This may be due to the model not being high capacity enough to fill in the texture transition, the dataset being limited, or the model needs to be trained for longer.

patch XtoY apples_and_oranges

patch + cycle XtoY apples_and_oranges

patch YtoX apples_and_oranges

patch + cycle YtoX apples_and_oranges
Figure. Patch vs DC Discriminator We see that the facial features on cats are significantly better on patch discriminator vs dc discriminator. In DC discrminator, a lot of faces are blurred and contain artifacts, however in patch discrminator, the faces are more detailed. This may be a benefit of using patch discrminator that focuses on patches, which captures more fine details, instead of overall image as a whole.
patch + cycle XtoY cats

dc + cycle XtoY cats
patch + cycle YtoX cats

dc + cycle YtoX cats
Figure. Patch vs DC Discriminator We see that both patch and DC discriminator perform reasonably on apples to oranges. Both capture color changes pretty well. The nature of the apples and oranges dataset makes it hard to tell which one is better. Both methods seem to retain enough details from the input images.
patch + cycle XtoY apples_and_oranges

dc + cycle XtoY apples_and_oranges
patch + cycle YtoX apples_and_oranges

dc + cycle YtoX apples_and_oranges
CycleGAN UNet
We implement a small UNet architecture on top of the given architecture to see if there are improvements. UNet, which is introduced for image segmentation and also used in pix2pix for image to image translation concatenates features from downsampling to the features while upsampling. This way, high resolution and low resolution features are fed into the upsampler, allowing the generator to generate images while taking in account high resolution features. All comparisons below are made with patch discrminator and cycle consistency loss.
Figure. UNet We see that UNet preserves a lot of features from the input image, sometimes even the edges of fur color change, which is undesirable. Additionally, UNet preserves eyes in almost the same location on the target domain cat. This can be a good thing or a bad thing. It is bad in that it may make the target domainc at look unreaslistic. It is good in that it preserves a lot of input features. UNet maybe better for style translation where we want to keep a lot of features from the input domain and we want less hallucination.
patch + cycle + dcgan XtoY cats

patch + cycle + unet XtoY cats
patch + cycle + dcgan YtoX cats

patch + cycle + unet YtoX cats
Figure. UNet We see that dcgan generator captures colors better than UNet generator for this dataset. While UNet keeps edges from input image well, it is not the most desirable when it comes to apples to oranges and vice versa. UNet works less well for this dataset.
patch + cycle + dcgan XtoY apples

patch + cycle + unet XtoY apples
patch + cycle + dcgan YtoX apples

patch + cycle + unet YtoX apples