Project 2
Gradient Domain Fusion
This project is an attempt to fuse a source foreground image onto a target background image by ensuring the continuity of pixel gradients around a 4-neighborhood.
Often, when we try to fuse two images together, we end up with images that seem unnatural, due to sharp constrasts in color, contrast and brightness around the boundaries between both images.
Therefore, to make the resultant image feel more natural, we aim to incorporate the "style" of one image into another by only retaining the relative structure of the other image.
Intuitively, this is achieved by manipulating pixel values in the target image while maintaining a similarity of gradients.
- For each pixel that is not masked in the target image, the value of the pixel is left unchanged.
- For each pixel that is in the mask of the target image, we adjust the pixel values to match that of the source image, while ensuring continuous gradients at the boundaries.
As long as the colors between the target background and source foreground are not too different, and that the orientations of each image are coherent, gradient domain fusion can produce an image that looks natural.
Toy Example
Before performing gradient domain fusion, a toy image is first used as an example to illustrate how to calculate gradients within a single image, and to use them to reconstruct the given image, given a single starting point.
To do so, all constraints are combined to form a linear system of equations, which can then be solved to recover the original image.
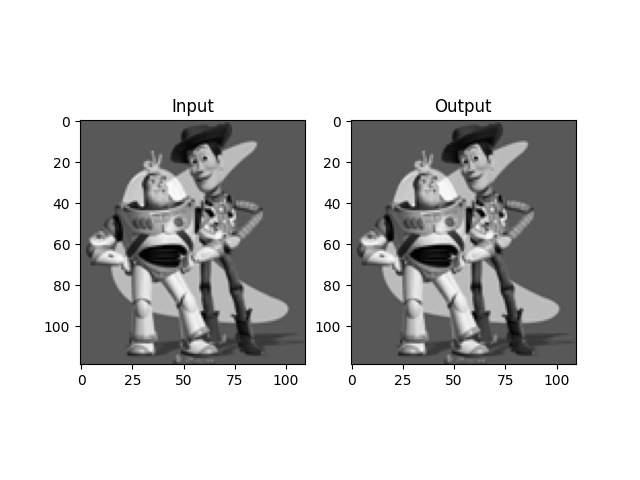
Examples of Source-Target Gradient Domain Fusion
In order to blend two images effectively, first, a rectangular region of interest that completely covers the source image is selected.
For each pixel in this region of interest, if the source image is not present, the constraint is simply set to v = b, where b is the value of the pixel in the target image.
If the source image is present, four constraints corresponding to the four directions are added into the linear system.
b is first set as the source gradient which we would like to mimic, and the element corresponding to the pixel location is set to 1 for A.
If the neighboring pixel is not in the source image, then we simply add its value to b. If it is, then we set -1 to the corresponding neighbor pixel location in A.
In doing so, a system of linear equations is created that is coherent with the minimization required for gradient domain fusion.
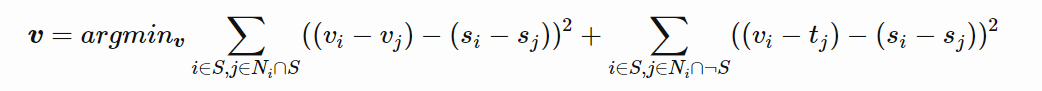
For each example, there are 4 options:
- Target Background Image
- Target Background Image with Source Directly Copied
- Naive Blending of Source and Target Images
- Poisson Blending of Source and Target Images
Click on the appropriate buttons to view each image.
Favourite Example: Plane and Helicopter





This combination works pretty well, most likely due to the original Helicopter image also being in the sky.
Example 1: Bear in Pool





This works relatively well, since the bear blends in pretty well with the water in the swimming pool.
However, the waves around the bear might not be coherent with the relatively still water, which results in a small peculiarity.
Example 2: Chicken in Forest





This is an example of a negative result, since the color of the chicken is completey different from its original color.
This is most likely due to the difference in background color, and the colors in the foreground image.
Example 4: Car on Road





While this seems to work relatively well, the appearance of the car seems a little too shiny, which again could perhaps be attributed to the dark patches surrounding the car in the original image.
Example 5: Tree in Desert





This works very nicely, other than the patch near the base of the tree.
There is some coloring issues as well, since the mask crop was not done very precisely, leading to the source image capturing some unwanted detail.
Challenges
- Overall, Poisson blending works relatively well as long as the images to be blended are semantically similar, and make sense within the context of each image.
- There are some issues that could lead to a degradation in performance, such as the quality of crop and the surrounding pixels in the source image.
- However, these form the minority of cases, and with careful selection of images, we can typically get realistic results.
Bells and Whistles
Mixed Gradients
Rather than trying to replicate the source image gradients, we could try to replicate the pointwise maximum of the source and target image gradients.
This allows us to mimic the gradients in the source image, while also including information in the target background image that might be semantically significant.
Overall, it is expected that the mixed gradients method will produce images which seem to be more "transparent", since some of the information in the background is retained.
Example 6: Treasure Map





The normal Poisson blending here doesn't work very well, as it looks like the words were just copied onto the background image.
With mixed blending, we are able to retain some structure from the background, leading to a better result that looks more natural, as if the words were indeed written on the paper.
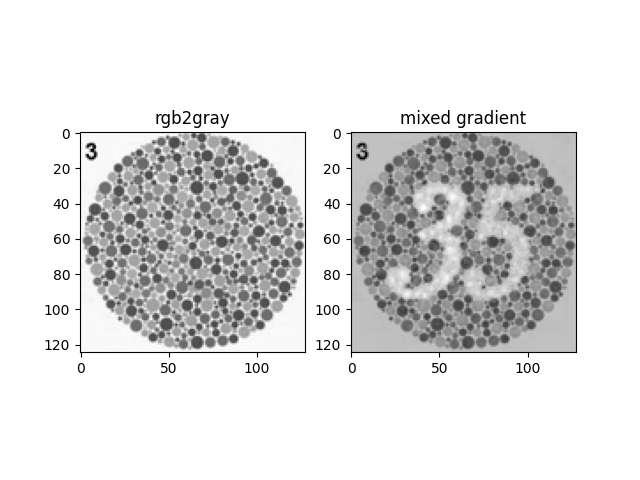
Color2Gray using HSV Channels
In order to improve contrast information in the converted grayscale images, we can use the HSV channels of the image as a gradient augmentation layer and apply mixed gradients.
Since the S (saturation) and V (value) channels provide information about the strength and the brightness of a pixel, these two channels are good candidates for gradient augmentation.
Saturation Channel-augmented Grayscale Image
Value Channel-augmented Grayscale Image
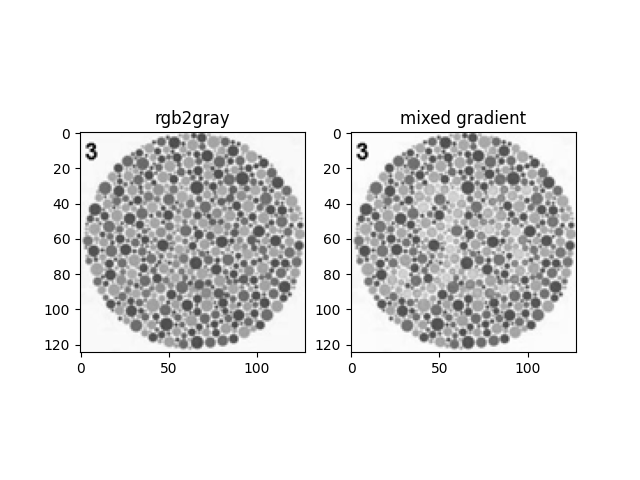
From these two results, we can see that the saturation channel is a better candidate for contrast augmentation.
We can also see that due to the need for pixels to scale towards more extreme values for a higher contrast, the overall image itself is perceived to be darker.