Project 3
Cats Generator Playground
This project aims to develop and train two types of Generative Adversarial Networks (GANs) from scratch.
- Deep Convolutional Generative Adversiarial Network (DCGAN)
- Cycle Generative Adversiarial Network (CycleGAN)
The DCGANs will be used to generate images of grumpy cats from noise, while the CycleGAN will be used to generate grumpy cats from Russian Blues and vice versa, as well as oranges from apples and vice versa.
Padding
For a convolutional layer, the output size is determined by the size of the input data, kernel size, stride and padding using the formula:
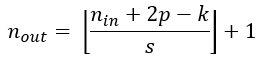
Given a kernel size of 4 and a stride of 2, the padding size for each image to allow for the input size to be halved is 1.
Deep Convolutional GANs
In training DCGANs, data augmentation techniques play an integral part in allowing the generator to generalize to a wider range of images, and preventing the discriminator from learning features specific to the dataset that might not be semantically representative.
Therefore, two regimes of data augmentation are specified:
- Basic Data Augmentation: a simple resize and normalization of the image
- Deluxe Data Augmentation: resize, random crop of approx. 90% of the image, a random horizontal flip and image normalization
Furthermore, to further prevent the discriminator from memorizing the dataset, differentiable augmentation is introduced to augment both generated and real images during training, which allow for a larger quantity of images without greatly modifying the original data distribution.
As a result, a total of four models were trained and the loss functions are displayed below:
- Basic Data Augmentation
- Deluxe Data Augmentation
- Basic Data Augmentation with Differentiable Augmentation
- Deluxe Data Augmentation with Differentiable Augmentation
Basic, Discriminator Loss

Basic, Generator Loss

Deluxe, Discriminator Loss

Deluxe, Generator Loss

Basic with Diff Aug, Discriminator Loss

Basic with Diff Aug, Generator Loss

Deluxe with Diff Aug, Discriminator Loss

Deluxe with Diff Aug, Generator Loss

One tricky aspect of training GANs is that, unlike conventional loss functions, there is a need to balance the strength of the discriminator and generator to ensure that neither overpowers the other.
For instance, if the generator has high loss, a good discriminator is useless since no useful images are generated.
On the other hand, a generator learns very slowly if the discriminator is unable to distinguish between real and fake images.
Therefore, a good training regime should see the discriminator loss first decrease, before the generator improves and is able to decrease its loss, at the expense of the discriminator since it is able to generate better quality images.
Sample Images: Effects of Data Augmentation
The following generated images show the differences between using basic data augmentation and deluxe data augmentation.
These examples also show the effect of using differentiable data augmentation.
DCGAN with Basic Data Augmentation, Iteration 6000

DCGAN with Basic and Differentiable Data Augmentation, Iteration 6000

DCGAN with Deluxe Data Augmentation, Iteration 6000

DCGAN with Deluxe and Differentiable Data Augmentation, Iteration 6000

Comparing the set of images that are generated with basic data augmentation and deluxe data augmentation, we can see that the quality of images generated with deluxe data augmentation is of higher quality.
By adding additional samples to the training data helps to enrich the training data distribution, since images of cats which are flipped or cropped are also semantically cats.
With the addition of differentiable data augmentation, the data augmentation operations are added both to real and generated images. Since the augmentations are differentiable, the losses can be backpropagated through these augmentations to update the respective models.
While it may not seem like there is much improvement to the images generated, we can see that there are fewer artifacts when differentiable augmentations are added.
Sample Images at Various Steps: DCGAN with Deluxe, Differentiable Data Augmentation
Some images were also sampled for the run using the deluxe data augmentation with differentiable augmentation, at different iteration points.
Click on the appropriate buttons to view each image generated at these iteration points.


Initially, the generator is only able to generate images which resemble the colors present in the training dataset, with weak features that are relatively blur.
However, after many iterations of training, the generator is able to produce images which are sharper, and possess strong features that are present in the original dataset. These images are much more likely to be sampled from the original data distribution.
CycleGANs
Grumpy and Russian Blue
Patch Discriminator, Iteration 1000, X to Y

Patch Discriminator, Iteration 1000, Y to X

Patch Discriminator with CCL, Iteration 1000, X to Y

Patch Discriminator with CCL, Iteration 1000, Y to X

Patch Discriminator, Iteration 10000, X to Y

Patch Discriminator, Iteration 10000, Y to X

Patch Discriminator with CCL, Iteration 10000, X to Y

Patch Discriminator with CCL, Iteration 10000, Y to X

The cycle consistency loss helps the training loop by producing images which have more common semantic features with the original image.
Without the cycle consistency loss, the generator only needs to produce an image that is likely given the data distribution, so that the discriminator is unable to tell that it is a generated image.
However, with the additional constraint that the image generated must produce a similar image when passed through the other generator, both generators are encouraged to retain as many latent features of the image as possible, to produce an image that closely resembles the original, but in a different style.
For example, one clear benefit of using the cycle consistency loss is that the direction of the head of the cat in the generated image is preserved, whereas the model trained without seems to lack this preservation.
In general, the addition of the cycle consistency loss while training helps to generate better images that closely resemble the input image.
Apples and Oranges
Patch Discriminator, Iteration 1000, X to Y

Patch Discriminator, Iteration 1000, Y to X

Patch Discriminator with CCL, Iteration 1000, X to Y

Patch Discriminator with CCL, Iteration 1000, Y to X

Patch Discriminator, Iteration 10000, X to Y

Patch Discriminator, Iteration 10000, Y to X

Patch Discriminator with CCL, Iteration 10000, X to Y

Patch Discriminator with CCL, Iteration 10000, Y to X

Likewise, the CCL loss helps to preserve features that are present in the original image. For instance, if the image has a black background, the generated image has a black background when using CCL.
CCL also helps when the input image is very different, such as when the image contains a basket of fruit. The model without CCL struggles to handle these images, whereas the inclusion of CCL produces images that are more believable.
Furthermore, CCL also helps with images where there is cut fruit open, allowing the textures in the cut section of the fruit to be replicated with higher quality and color accuracy.
Grumpy and Russian Blue with DCDiscriminator
The effects of using the patch discriminator can be analyzed by looking at the output of the generative model using the original DCDiscriminator.
Patch Discriminator with CCL, Iteration 10000, X to Y
Patch Discriminator with CCL, Iteration 10000, Y to X
DCDiscriminator with CCL, Iteration 10000, X to Y

DCDiscriminator with CCL, Iteration 10000, Y to X

When trained on the DCDiscriminator loss, we notice that the images produced are more realistic.
As compared to these images, those trained under the patch discriminator have more structure, rather than these images which have segments that resemble the colors that make up a cat, but do not form a coherent picture.
This could be attributed to the fact that the patch discriminator is able to identify specfiic parts of the image that are less believable, such that the loss can be propagated to improve the quality of that segment of the image.
Apple and Oranges with DCDiscriminator
Patch Discriminator with CCL, Iteration 10000, X to Y
Patch Discriminator with CCL, Iteration 10000, Y to X
DCDiscriminator with CCL, Iteration 10000, X to Y

DCDiscriminator with CCL, Iteration 10000, Y to X

Likewise, the patch discriminator performs better here when multiple fruit are present in the image, and the DCDiscriminator tends to perform poorly.
This could be because the DCDiscriminator lacks the ability to replicate textures in the target distribution, leading to strange artifacts and a distortion of the images.
Overall, the images that are generated using the patch discriminator seem more believable, especially when the image has complex features.
Bells and Whistles
Spectral Normalization for DCDiscriminator
To prevent weights from exploding or diminishing due to propagated gradients, we can utilize a more sophisticated form of normalization known as spectral normalization.
Spectral normalization restricts the maximum singular value of the weights such that the Lipschitz constant of the network is limited, allowing for greater continuity.
DCGAN with Deluxe and Differentiable Data Augmentation, Iteration 6000
DCGAN with Deluxe and Differentiable Data Augmentation and Spectral Normalization, Iteration 6000

Spectral normalization improves the quality of the images produced.
Diffusion
With the advent of diffusion techniques, an attempt to generate Grumpy Cats was made on the given dataset.
A U-Net model was implemented, together with the training loop to denoise images at randomly chosen time steps.
A linear beta decay schedule was also implemented, where each value of beta is evenly spaced.
A total of 2000 iterations of training were carried out, and 32 sample images were sampled from the produced model.

Even with 2000 iterations, the images produced are relatively realistic, with the exception of red patches that are present in small quantities.
Based on these results, if the model were to be trained on a larger dataset and for several more thousand iterations, it is likely possible to get a generator that is able to produce high-quality images that represent a wider and more diverse range of cats.