Assignment #3 - Cats Generator Playground
Background
GAN is a type of generative model that can sample domain images from random noises. This assignment shows its power in generating images and transfering unpaired images. Both of them reveal GAN's well-learned domain distribution knowledge. The following also shows the effectiveness of specific data augmentation and loss design in training GAN.
Motivation
- Generate Grumpy cat images from noise.
- Convert
Grumpy/Russian Blue&Apple/Orange
Vanilla GAN
This is a modified version of DCGAN, where the transpose conv in Generator is replaced by upsample of factor 2 and conv.
For the Discriminator structure,
- Kernel Size
K: 4 - Stride
S: 2 - Input Size
I: 64 - Output Size
O: 32 - Padding
P: ?
We have
The padding P of conv1~conv4 should be 1, and P of conv5 should be 0.
K, P, S in Generator can also be inferenced by this formula.
It is worth mentioning that, the activation function of conv5 has to be tanh, because I misused the relu first and find the generator very difficult to learn from noise.
I read a survey which happend mentioning the choice of activation function of DCGAN:
'except the final layer which had tanh activation, allowing the model to learn quicker to convergence and utilize the whole spectrum of the colours from the training data'.
It seems the model got bad performance using 'relu' in the last layer of G because of its smaller slope and non-negative output value.
Also, the implementation of .detach() here is essential. It determines whether the gradient updates could be passed to the Generator.
Diffaug
As stated in the paper, Diffaug conduct augmentation on both the fake images and the real images, implementing on training both G and D.

fig.4 in the paper
In our case, using diffaug (color, translation, and cutout) benefits the training.
- Provide a more efficient gradient in updating G. The D_loss converges to a larger value since the augmentation makes the discriminator harder to distinguish between real and fake images. The converged G_loss turns to be smaller, indicating a higher quality of generated samples.
- Diversify the training data for a better performance on small datasets
The cat datasets only have hundreds of images, making the
Geasy to memory all training samples, instead of learning data distribution.
Here are the training losses (better viewed after smoothing).

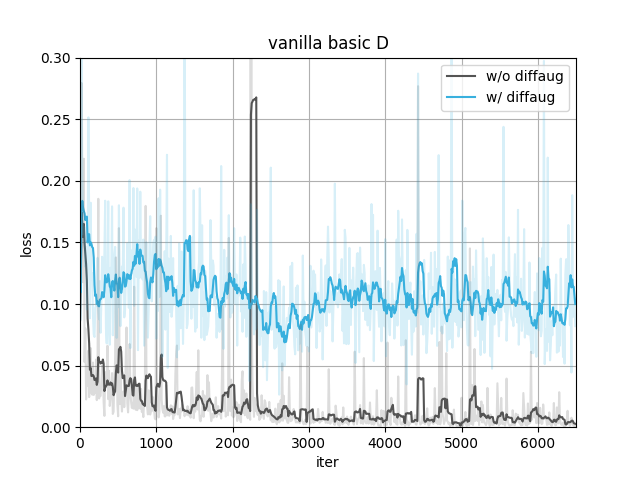
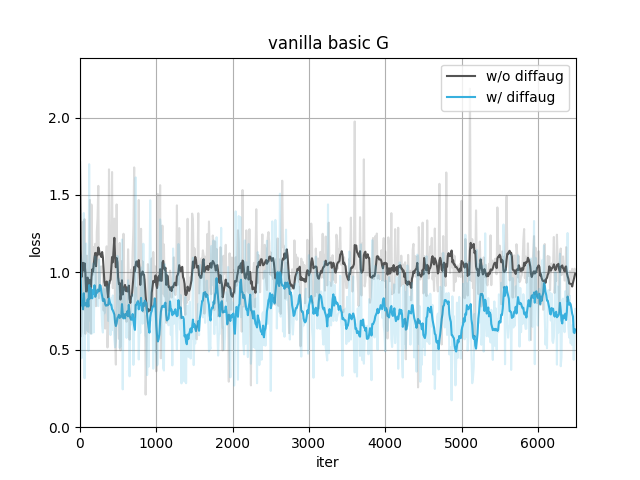
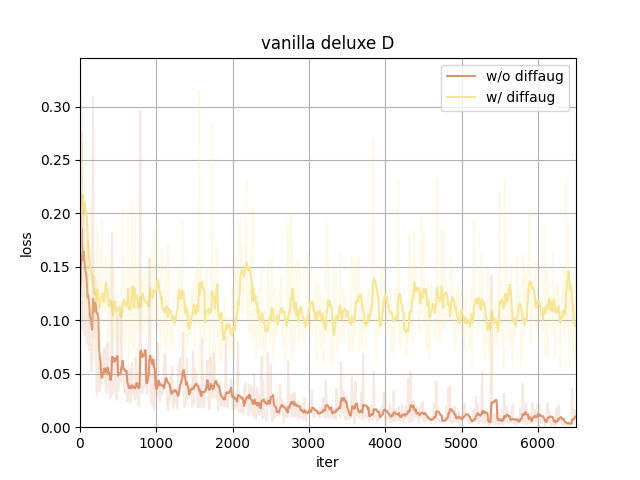
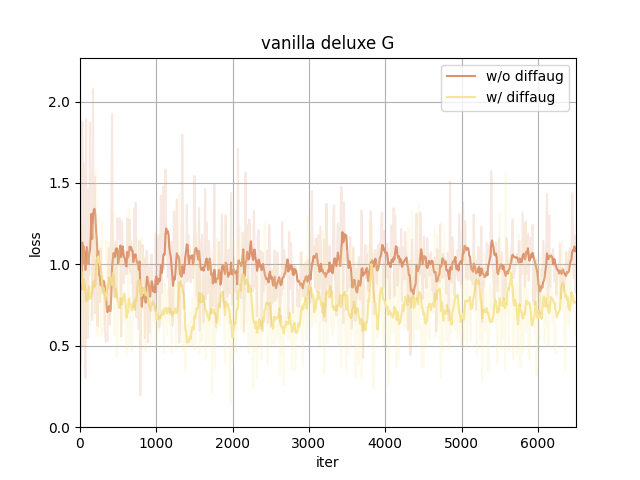
With the same type of date preprocessing, adding diffaug makes D converge to a larger loss and G to a smaller, meaning the generated samples have a better quality to fool the discriminator.
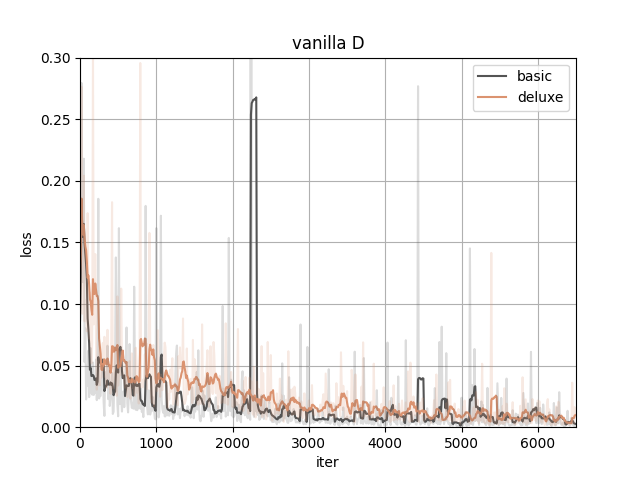
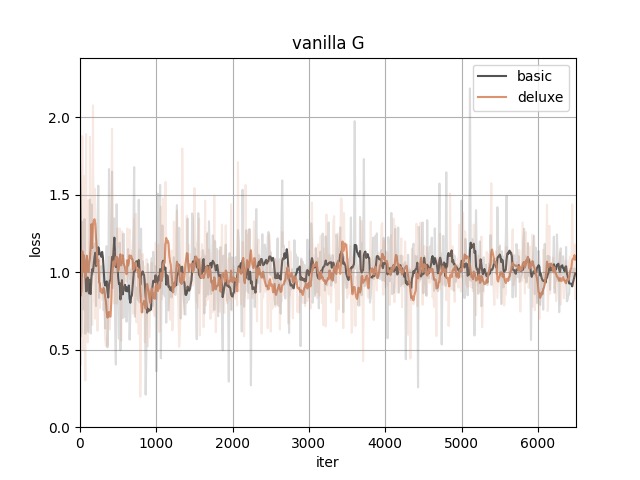
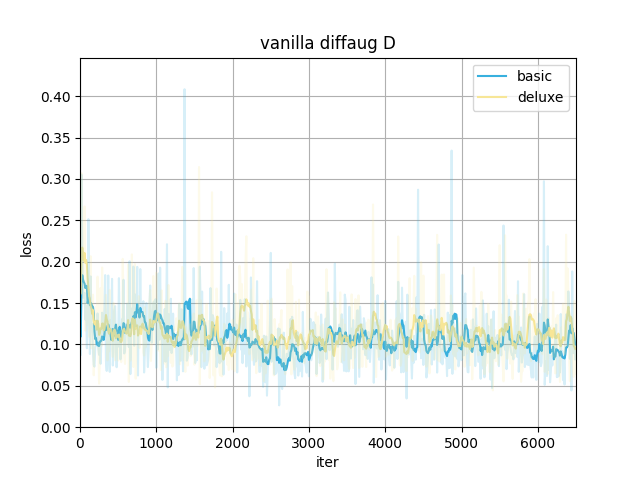
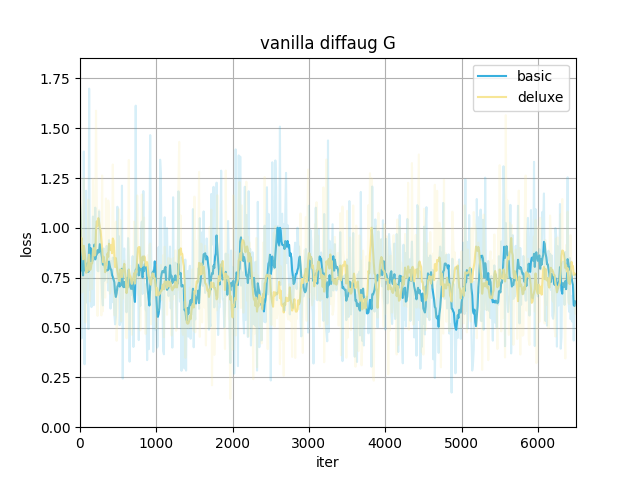
The data preprocessing(to the real images only) itself doesn't show much difference here.



200 steps -- 1200 steps -- 6200 steps
w/ diffaug
Results show the model is less likely to collapse after several training stages w/ diffaug.
Diffusion
I think the diffusion-generated images have better details compared to GAN-generated images and have fewer color artifacts. But maybe the training set is not large enough for the model to modulate the 'grumpy' distribution. Some images just look furry but not really cat-like.

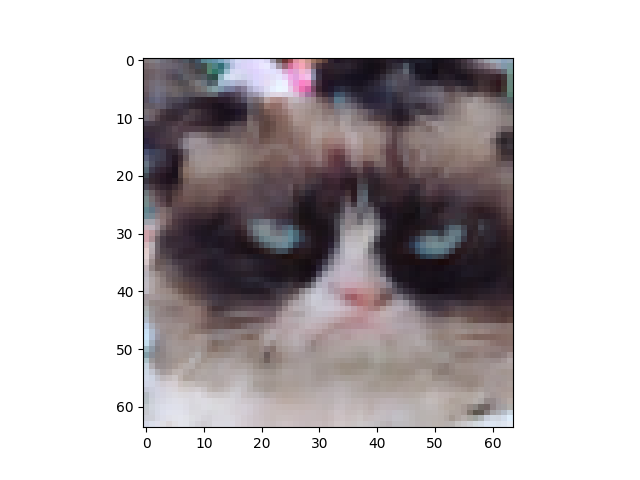

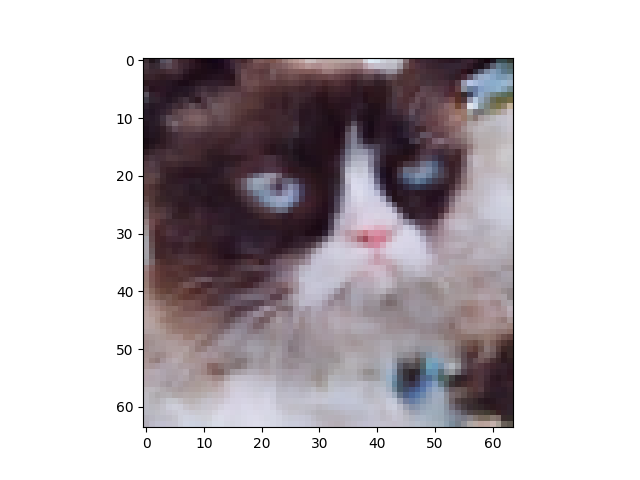
diffusion output samples
GAN-based training is fast but its results seem less diverse than the diffusion-based method's.
Comparing GAN and diffusion models, the former has less training cost and can generate decent results. The latter is capable of generating more high-quality and detailed samples but requires more time to train and a larger dataset. Moreover, it is easier for diffusion-based methods to balance control and diversity.
Cycle GAN
Grumpy/Russian Blue
Click the corresponding position on silder to switch.patch-w/o cycle loss
w/ augmentation, the models are less likely to collapse, since the diverse input brings difficult to the Discriminator in distinguishing real and fake samples.
patch-w/ diffaug
w/ consistency loss, the intermediate outputs are less likely to have outliers. The structure i.e. border shape of generated sample
patch-w/ diffaug-w/ CCL
It is also important to set the magnitude of the lambda_cycle properly, since too small cannot contribute, but too large limits the potential of transferation (see the 1w steps' results).
patch-w/ diffaug-w/ CCL(lambda=1)
For the discriminator, actually I like the results from DCDiscriminator which look more natural. With DCDiscriminator, the generated samples show a severe change in the very beginning. PatchDiscriminator on the contrary, tightly constraints the details of each patch, slowing down the updating. But I think the preference of dc or patch depends on the application scenarios. By saying 'natural' I mean the generated sample from Grumpy is more like a real Russian Blue cat, with an almond face and clear yellow-green eyes. However, the color contrast, local texture, and global shape can be better preserved by PatchDiscriminator. This features contribute more to identity. So if the detail preserving is preferred, then patch is probably a better choice.
Apple/Orange
Here are the results on the Apple/Orange dataset.
w/ diffaug-w/o CCL
w/ diffaug-w/ CCL(lambda-1)
I find some interesting phenomenons about the bias in datasets. For example, it is hard for the model to transfer green apple to orange or transfer a cut apple to a cut orange. Because the proportion of green apple and cut fruits images is small in the training data, the model have no idea what the inner side of fruits looks like and it not sure how to map a rarely find color in the original domain to the color in the target domain. Also, if there is another main object e.g. human face, the model cannot get its semantic meaning, but regards it as a weird fruit.